LINQ to SQL (Part 7 - Updating our Database using Stored Procedures)
Over the last few weeks I've been writing a series of blog posts that cover LINQ to SQL. LINQ to SQL is a built-in O/RM (object relational mapper) that ships in the .NET Framework 3.5 release, and which enables you to model relational databases using .NET classes. You can use LINQ expressions to query the database with them, as well as update/insert/delete data.
Below are the first six parts in this series:
- Part 1: Introduction to LINQ to SQL
- Part 2: Defining our Data Model Classes
- Part 3: Querying our Database
- Part 4: Updating our Database
- Part 5: Binding UI using the ASP:LinqDataSource Control
- Part 6: Retrieving Data Using Stored Procedures
In part 6 I demonstrated how you can optionally use database stored procedures (SPROCs) and user defined functions (UDFs) to query and retrieve data using your LINQ to SQL data model. In today's blog post I'm going to discuss how you can also optionally use SPROCs to update/insert/delete data from the database.
To help illustrate this - let's start from scratch and build-up a data access layer for the Northwind sample database:
Step 1: Creating our Data Access Layer (without using SPROCs yet)
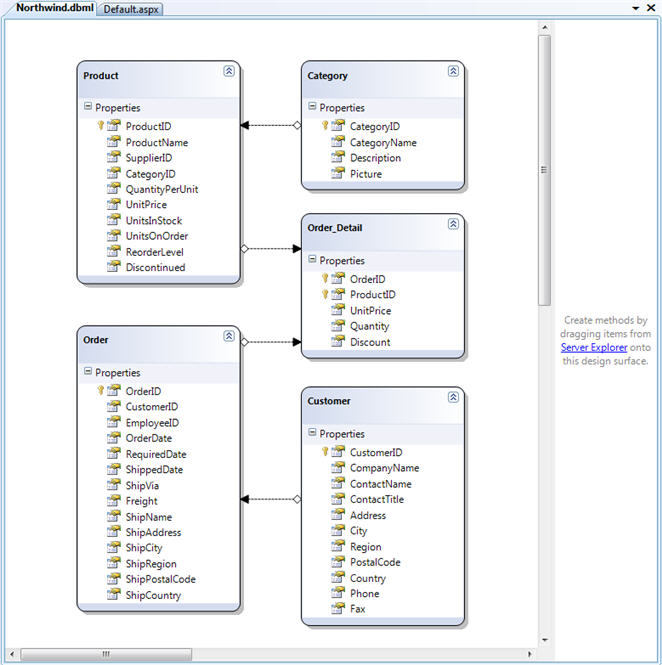
In my Part 2: Defining our Data Model Classes tutorial I discussed how to use the LINQ to SQL ORM designer that is built-in to VS 2008 to create a LINQ to SQL class model like below:
Adding Validation Rules to our Data Model Classes
After defining our data model classes and relationships we'll want to add some business logic validation to our data model. We can do this by adding partial classes to our project that add validation rules to our data model classes (I cover how to-do this in-depth in my Part 4: Updating our Database LINQ to SQL tutorial).
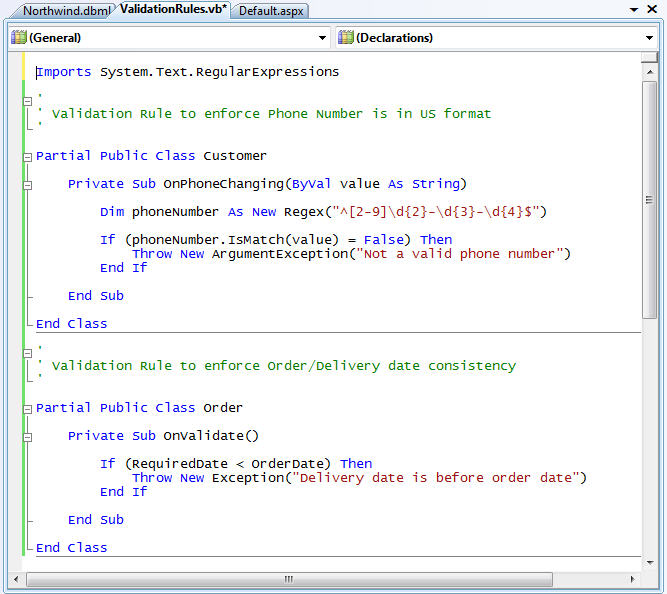
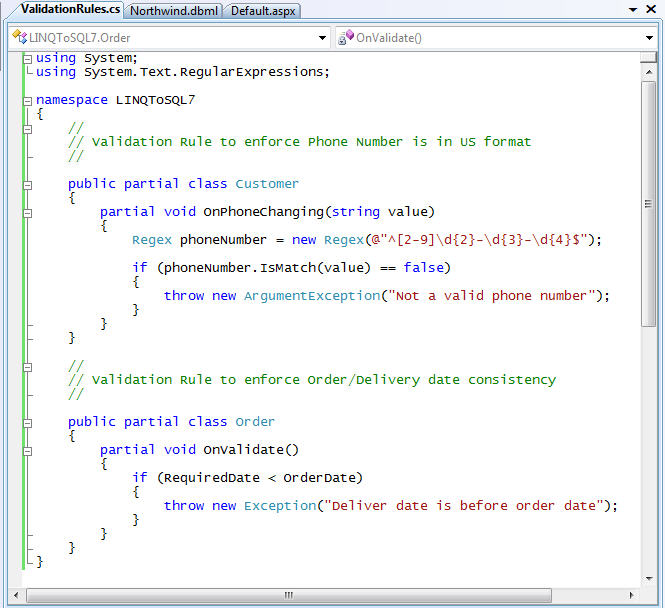
For example, we could add validation rules to enforce that the Customer's phone number follows a valid phone pattern, and that we don't add Orders where the customer's RequiredDate for delivery is before the actual OrderDate of the Order. Once defined in partial classes like below, these validation methods will automatically be enforced anytime we write code to update our data model objects in an application.
VB:
C#:
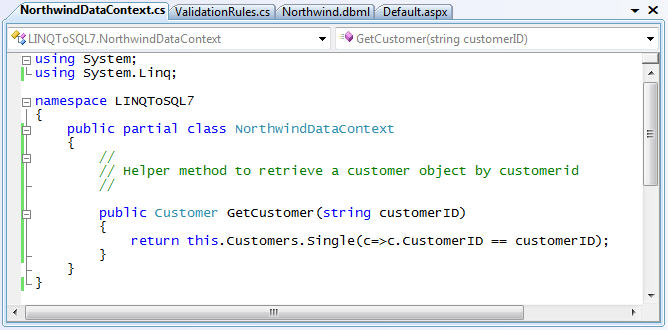
Adding a GetCustomer() Helper Method to our DataContext
Now that we have our data model classes created, and have applied validation rules to them, we can query and interact with the data. We can do this by writing LINQ expressions against our data model classes to query the database and populate them (I cover how to-do this in my Part 3: Querying our Database LINQ to SQL tutorial). Alternatively we could map SPROCs to our DataContext and use them to populate the data model classes (I cover how to-do this in my Part 6: Retrieving Data using Stored Procedures LINQ to SQL tutorial).
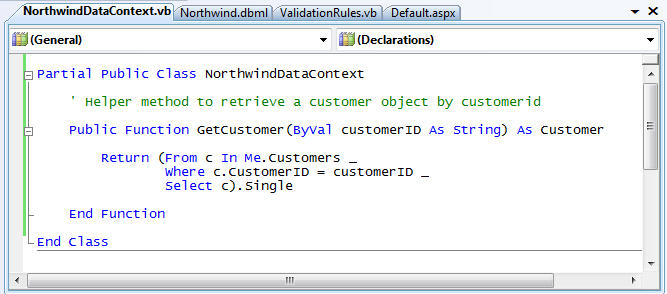
When building a LINQ to SQL data layer you'll usually want to encapsulate common LINQ queries (or SPROC invocations) into helper methods that you add to your DataContext class. We can do this by adding a partial class to our project. For example, we could add a helper method called "GetCustomer()" that enables us to lookup and retrieve a Customer object from the database based on their CustomerID value:
VB:
C#:
Step 2: Using our Data Access Layer (still without SPROCs)
We now have a data access layer that encapsulates our data model, integrates business validation rules, and enables us to query, update, insert, and delete the data.
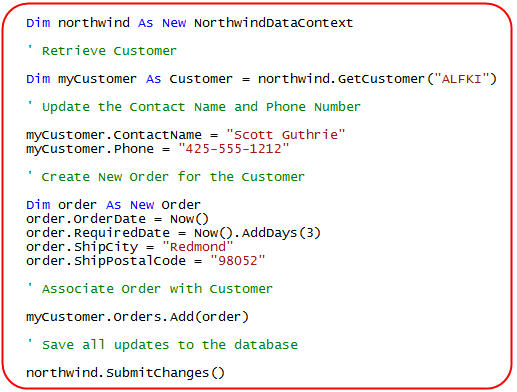
Let's look at a simple scenario using it where we retrieve an existing customer object, update the customer's ContactName and Phone Number, and then create a new Order object and associate it with them. We can write the below code to do all of this within a single transaction. LINQ to SQL will ensure that our business logic validation rules are clean before saving anything in the database:
VB:
C#:
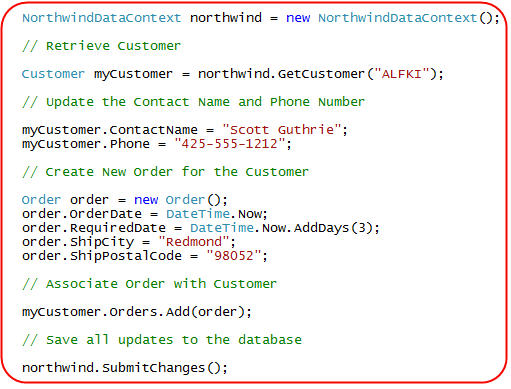
LINQ to SQL monitors the modifications we make to the objects we retrieve from the DataContext, and keeps track of all of the objects we add into it. When we call DataContext.SubmitChanges() at the end, LINQ to SQL will check that our business logic rules are valid, and if so automatically generate the appropriate dynamic SQL to update our Customer record above, and insert a new record into the Orders table.
Hang on a second - I thought this post was about using SPROCs???
If you are still reading this, you might be feeling confused about where SPROCs fit into this post. Why did I show you above how to write code that works with our data model objects, and then causes dynamic SQL to run? Why haven't I showed you how to call a SPROC for doing inserts/updates/deletes instead yet?
The reason is that the programming model in LINQ to SQL for working with data model objects backed by SPROCs is the same as those updated via dynamic SQL. The way you add data model validation logic is exactly the same (so all the validation rules on our data model classes above still apply when we use SPROCs). The code snippet above where we use our data access layer to retrieve a customer, update it, and then add a new order associated with it is also exactly the same regardless of whether we are using dynamic SQL for updates, or whether we have configured our data model classes to use SPROCs instead.
This programming model symmetry is powerful both in that you don't have to learn two ways of doing things, and also because it means that you don't have to decide up front at the beginning of your project whether you are going to use SPROCs or not. You can start off using the dynamic SQL support provided by the LINQ to SQL ORM for all queries, inserts, updates and deletes. You can then add your business and validation rules to your model. And then later you can optionally update your data mapping model to use SPROCs - or not if you decide you don't want to. The code and tests you write against your data model classes can stay the same regardless of whether you use dynamic SQL or SPROCs.
We'll now spend the rest of this blog post demonstrating how we can update the data model we've built to use SPROCs for updates/inserts/deletes - while still using the same validation rules, and working with the same code snippets above.
How to Use SPROCs for Insert/Update/Delete Scenarios
We can modify the data access layer we've been building to use SPROCs to handle updates, instead of dynamic SQL, in one of two ways:
1) By using the LINQ to SQL designer to graphically configure SPROCs to execute in response to Insert/Update/Delete operations on our data model classes.
or:
2) By adding a NorthwindDataContext partial class in our project, and then by implementing the appropriate Insert/Update/Delete partial methods provided on it (for example: InsertOrder, UpdateOrder, DeleteOrder) that will be called when we insert/update/delete data model objects. These partial methods will be passed the data model instances we want to update, and we can then execute whatever SPROC or SQL code we want to save it within the database.
When we use approach #1 (the LINQ to SQL designer) to graphically configure SPROCs to call, it is under the covers generating the same code (in a partial class it creates) that you'd write when using approach #2. In general I'd recommend using the LINQ to SQL designer to configure the SPROCs for the 90% case - and then in more advanced scenarios go in and custom tweak the SPROC invocation code it generates if you need to.
Step 3: Doing Order Inserts with a SPROC
We'll begin switching our data model to use SPROCs by starting with the Order object.
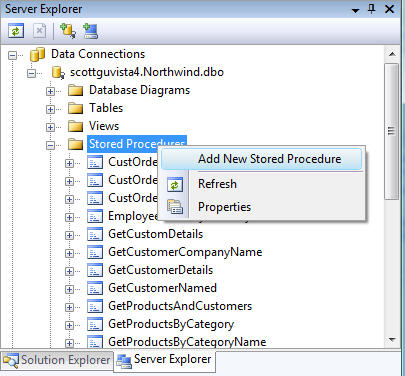
We'll first go to the Visual Studio "Server Explorer" window, expand into the "Stored Procedures" node of our database, and then right-click and choose "Add New Stored Procedure":
We'll then create a new SPROC that we'll call "InsertOrder" that inserts a new order record into our Orders table:
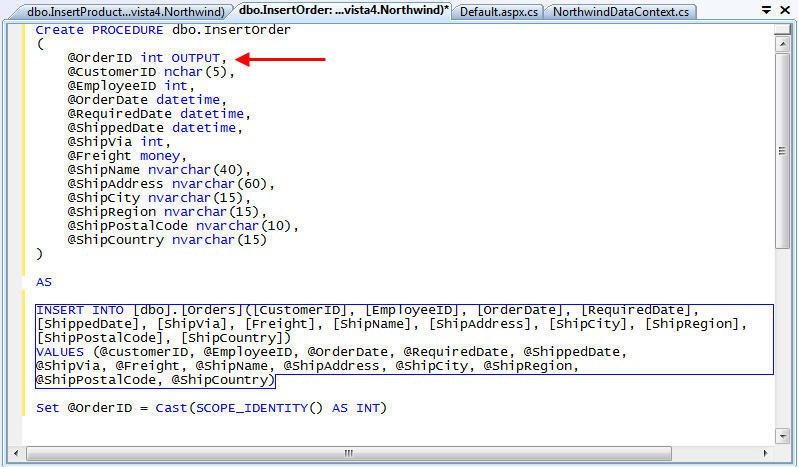
Notice above how the SPROC defines the "OrderID" parameter as an output param. This is because the OrderID column in the database is an identity column that is set to auto-increment each time a new record is added. The caller of the SPROC will pass in NULL as a value when calling it - and the SPROC then passes back the newly created OrderID value as the output value (by calling the SCOPE_IDENTITY() function at the end of the SPROC).
After creating the SPROC we'll then open up the LINQ to SQL ORM designer for our data access layer. Like I discussed in my last blog post in this series (Part 6: Retrieving Data Using Stored Procedures), we can drag/drop SPROCs from the server-explorer onto the method pane of our DataContext designer. We'll want to-do this with our newly created InsertOrder SPROC:
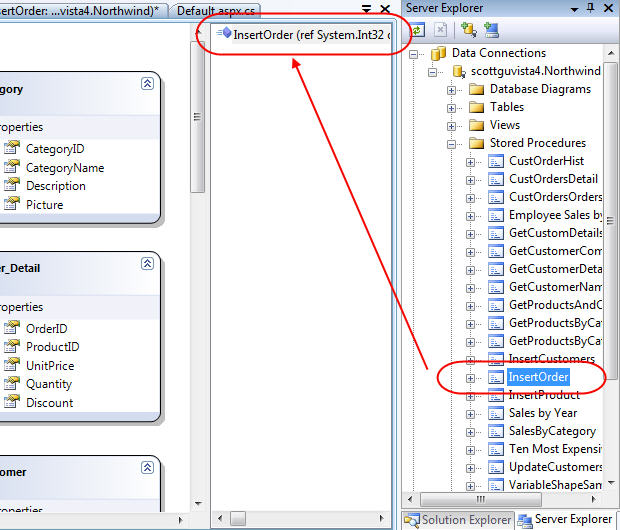
Our last step will be to tell our data access layer to use the InsertOrder SPROC when inserting new Order objects into the database. We can do that by selecting the "Order" class in the LINQ to SQL ORM designer, and then by going to the property grid and clicking the "..." button to override how Insert operations happen for it:
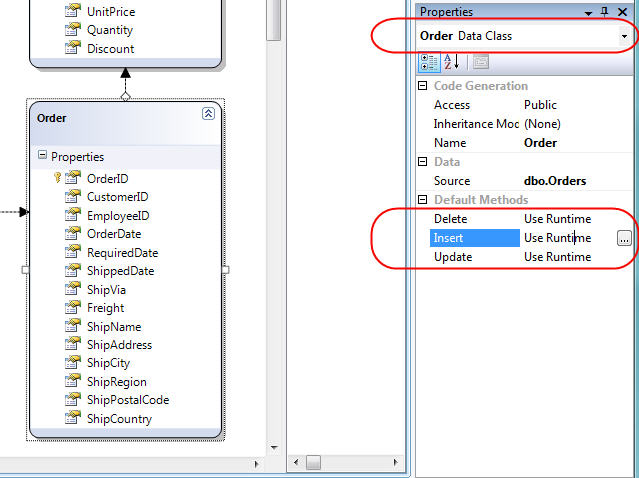
Clicking the "..." button will bring up a dialog that allows us to customize how insert operations happen:
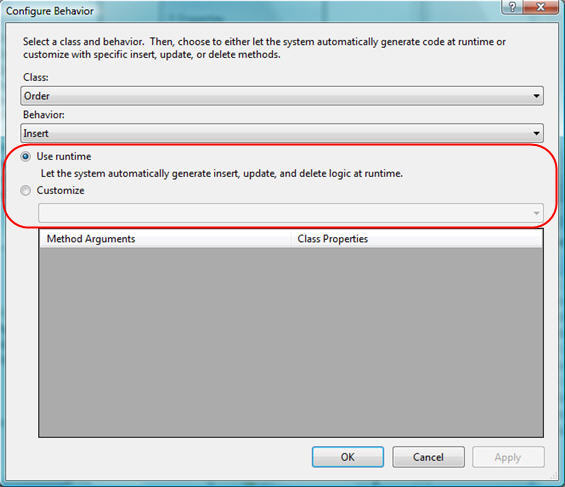
Notice above how the default mode ("Use Runtime") is to have LINQ to SQL calculate and execute dynamic SQL to handle the insert operations. We can change that by selecting the "Customize" radio button and then pick our InsertOrder SPROC from the list of available SPROCs:
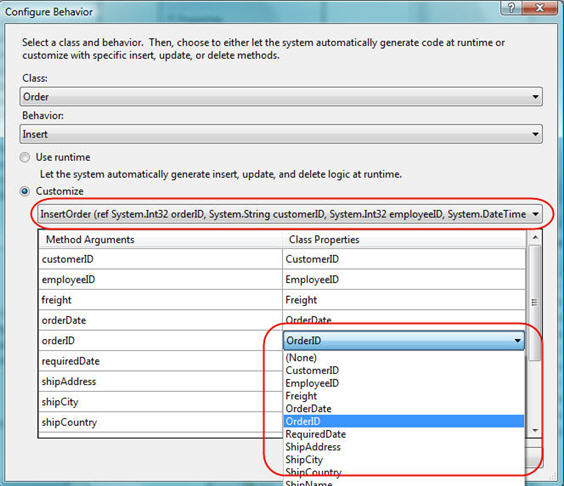
The LINQ to SQL designer will populate a parameter list for the SPROC we picked, and enable us to map properties on our Order class to parameters of our InsertOrder SPROC. By default it is smart and tries to "best match" them based on name. You can go in and override them if you want.
Once we click "ok" on the dialog, we are done. Now whenever a new Order is added to our DataContext and the SubmitChanges() method is invoked, our InsertOrder SPROC will be used instead of executing dynamic SQL.
Important: Even though we are now using a SPROC for persistence, the custom Order "OnValidate()" partial method we created earlier (in step 1 of this blog post) to encapsulate Order validation rules still executes before any changes are saved or the SPROC is invoked. This means we have a clean way to encapsulate business and validation rules in our data models, and can re-use them regardless of whether dynamic SQL or SPROCs are used.
Step 4: Doing Customer Updates with a SPROC
Now let's modify our Customer object to handle updates using a SPROC.
We'll start by creating a new "UpdateCustomer" SPROC like below:
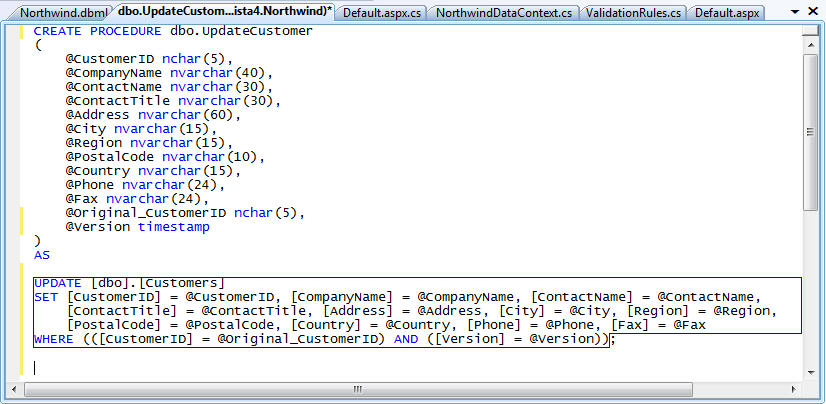
Notice above how in addition to passing in the @CustomerID parameter, we are also passing in a @Original_CustomerID parameter. The CustomerID column in the Customers table is not an auto-increment identity column, and it can be modified as part of an update of the Customer object. Consequently we need to be able to provide the SPROC with both the original CustomerID and the new CustomerID in order to update the record. We'll look at how we map this using the LINQ to SQL designer shortly.
You'll notice above how I'm also passing in a @Version parameter (which is a timestamp) to the SPROC. This is a new column I've added to the Northwind Customers table to help handle optimistic concurrency. I will cover optimistic concurrency in much more depth in a later blog post in this LINQ to SQL series - but the short summary is that LINQ to SQL fully supports optimistic concurrency, and enables you to use either a version timestamp or to supply both original/new values to your SPROCs to detect if changes have been made by another user since you last refreshed your data objects. For this sample I'm using a timestamp since it makes the code much cleaner.
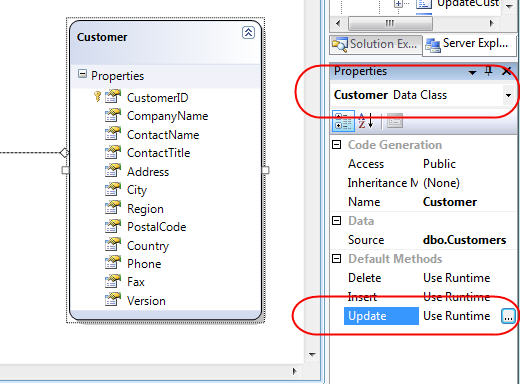
Once we've created our SPROC, we can drag/drop it onto the LINQ to SQL designer to add it as a method on our DataContext. We can then select the Customer class in the ORM designer and click the "..." button to override the Customer object's Update behavior in the property grid:
We'll select the "Customize" radio button and pick our UpdateCustomer SPROC to use:
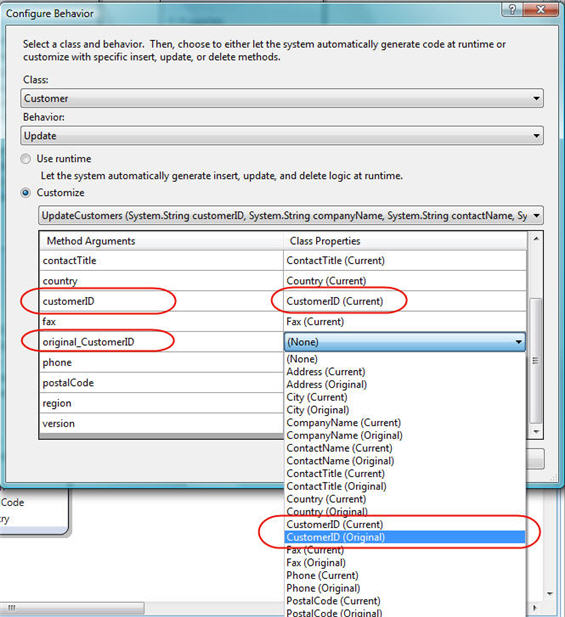
When mapping our Customer object's properties to the SPROC parameters, you'll notice that we'll want to be deliberate about whether we supply the "current" property value on the data object, or the original value that was in the database when the object was first retrieved. For example, we'll want to make sure we map the "current" value of the Customer.CustomerID property for the @CustomerID SPROC parameter, and that we map the original value for the @original_customerID SPROC parameter.
Once we click "ok" on the dialog, we are done. Now whenever a new Customer is updated and the SubmitChanges() method is invoked, our UpdateCustomer SPROC will be used instead of executing dynamic SQL.
Important: Even though we are now using a SPROC for persistence, the Customer "OnPhoneChanging()" partial method we created earlier (in step 1 of this blog post) to encapsulate Phone Number validation rules still executes before any changes are saved or the SPROC is invoked. We have a clean way to encapsulate business and validation rules in our data models, and can re-use them regardless of whether dynamic SQL or SPROCs are used.
Step 5: Using our Data Access Layer Again (this time with SPROCs)
Once we've updated our data layer to use SPROCs instead of dynamic SQL for persistence, we can re-run the exact same code we wrote in Step 2 earlier against our data model classes:
Now the updates for the Customer object, and the insert for the Order object, are executing via SPROCs instead of dynamic SQL. The validation logic we defined still executes just like before, though, and the data access code we write to use the data model classes is exactly the same.
Some Advanced Notes When Using SPROCs
A few quick notes that you might find useful for more advanced SPROC scenarios with LINQ to SQL:
Usage of SPROC Output Params:
In the Insert scenario (Step 3) above I showed how we could return back the new OrderID value (which is an auto-increment identity column in the Orders table) using an output parameter of the SPROC. You aren't limited to only returning back identity column values when using SPROCs with LINQ to SQL - in fact you can update and return back output values for any parameter of your SPROC. You can use this approach both for Insert and Update scenarios. LINQ to SQL will then take the return value and use it to update the property value of your data model object without you having to-do any second queries against the database to refresh/populate them.
What Happens if the SPROC Throws an Error?
If a SPROC raises an error when doing an Insert/Update/Delete operation, LINQ to SQL will automatically cancel and rollback the transaction of all changes associated with the current SubmitChanges() call on the DataContext. This ensures that your data is always kept in a clean, consistent state.
Can you write code instead of using the ORM designer to call SPROCs?
As I mentioned earlier in this post, you can use either the LINQ to SQL ORM designer to map your insert/update/delete operations to SPROCs, or you can add partial methods on your DataContext class and programmatically invoke them yourself. Here is an example of the explicit code you could write in a partial class for the NorthwindDataContext to override the UpdateCustomer behavior to call a SPROC:
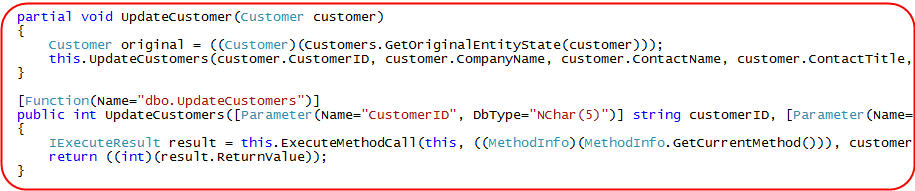
The code above was actually what was generated by the LINQ to SQL ORM designer when we used the designer to map the SPROC and then associate the update behavior of the Customer object with it. You can use it as a starting point and then add any additional logic you want to it to make it more advanced (for example: use the return value of the SPROC to raise custom exceptions for error conditions, optimistic concurrency, etc).
Summary
LINQ to SQL is a very flexible ORM. It enables you to write clean object-oriented code to retrieve, update and insert data.
Best of all - it enables you to cleanly design data model classes independent of how they are persisted and loaded from a database. You can use the built-in ORM engine to efficiently retrieve and update data in the database using dynamic SQL. Or alternatively you can configure your data layer to use SPROCs. The nice thing is that your code consuming the data layer, and all of the business logic validation rules you annotate it with, can be the same regardless of which persistence approach you use.
In future blog posts in this series I'll cover some remaining LINQ to SQL concepts including: Single Table Inheritance, Deferred/Eager Loading, Optimistic Concurrency, and handling Multi-Tier scenarios. I'm on vacation next week, and so will hopefully have some free time to get a few of them written then.
Hope this helps,
Scott