Building an associative (data)base - or: The Pile thinking applied
Ok, finally - after another digression on Pile fundamentals (and I guess, more needs to be said, but not right now) - I´ll quickly describe my prototype implementation of a Pile engine as well as a Pile agent/client to use it for searching in plain text files.
As stated earlier, the general architecture for my little full text search solution is simple:
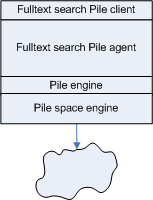
There is just one application (process) hosting the GUI frontend...
...the Pile agent which actually does the full text search, and the basic Pile management code split into a Pile engine and a Pile space engine.
Of course much can be improved in my code. So take it as a first prototype and venture into the realm of Pile. It´s implements just an in-memory Pile and is not fit for multithreading. But it helped me to switch my thinking from data to associations.
Lets start from the bottom up...
A prototype Pile space engine
The Pile space engine is the low level component encapsulating a Pile. The Pile space engine provides an interface to manage the 2D Pile handle space described in my previous posting. Remember the coordinate system?
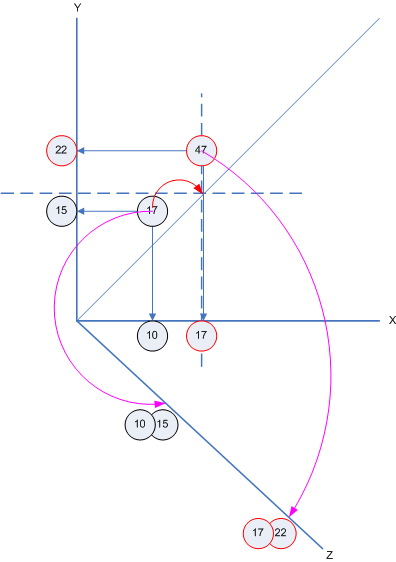
To view relations as points in this 2D space with an additional 3rd axis to map them back to their parents, is as fundamental as you can get, I think. Each relation is a point addressed by an x and y coordinate handle(r)=(handle(x), handle(y)). Each such point in the 2D space has a value, it´s handle, which also encodes the relation´s Qualifier.
x and y are the parent relations of r. And the x/y-coordinates are the handles of the parents.
To map a relation back to it´s parents the z-axis is introduced. Each point on it corresponds to a relation and contains the handles of its parents. (handle(x), handle(y)) = z(handle(r)).
How such a Pile space is implemented, I though, should be hidden within a component or at least behind an interface. So I set up this C# interface to describe all necessary operations to create and traverse relations in the Pile space:
namespace pile.engine32.contracts
{
public interface IPileHandleSpace
{
int CreateHandle(byte qualifier);
void SetHandle(int xHandle, int yHandle, int h);
int[] GetCorrdinatesForHandle(int h);
int GetHandleByCoordinates(int xHandle, int yHandle);
int[] FindHandlesByCoordinate(int coordHandle, bool followNormativeManner, byte qualifierFrom, byte qualifierTo);
byte GetQualifier(int handle);
}
}
CreateHandle() creates a new handle for a given Qualifier out of nothing. The Pile space engine does not set up a relation by itself, but just manages some 2D space of handles. So there is no need to pass informations on parents of a new relation to CreateHandle().
SetHandle() stores a handle at the given coordinates in the space. Also it registers the handle on the z-axis to be able to get at its parents.
GetCoordinatesForHandle() retrieves the parent handles for a handle. The int-array contains to items - or is empty is the handle does not exist.
GetHandleByCoordinates() retrieves the handle at a specific x/y-coordinate in the Pile space.
FindHandlesByCoordinate() retrieves for a given handle all the handles to which it is a x- or y-coordinate. Whether coordHandle is to interpreted as an x- or y-coord signifies followNormativeManner. It the flag is true, the handle is the x-coord, otherwise the y-coord. The Qualifier parameters are supposed to constrain the handles returned to a range of Qualifier values. Example: Retrieve all handles, where coordHandle is the x-coord (followNormativeManner == true) and the Qualifier is between 10 and 12.
Relations are represented by 32-bit integers in my Pile implementation. Qualifiers are 8-bit values.
For each Qualifier the Pile space engine keeps a counter. Creating a new handle thus is just a matter of incrementing this counter.
private int[] qualifierCounters = new int[256];
public int CreateHandle(byte qualifier)
{
return ((int)qualifier) << 24 | ++qualifierCounters[qualifier];
}
Since the 2D space is only sparsely populated with handles, it cannot be represented by a 2D-array. I thus chose a two level data structure consiting of dictionaries:
private Dictionary<int, Dictionary<int, int>> xAxis = new Dictionary<int,Dictionary<int,int>>();
private Dictionary<int, Dictionary<int, int>> yAxis = new Dictionary<int, Dictionary<int, int>>();
xAxis[xHandle] stores a list of y-handles together with the handles both are pointing to:
rHandle = xAxis[xHandle][yHandle]
This is sufficient for GetHandleByCoordinate() and SetHandle() and FindHandlesByCoordinate() with followNormativeManner==true. If followNormativeManner is false, though, a second axis data structure is needed to be able to retrieve handles via their y-parent-coordinate.
rHandle = yAxis[yHandle][xHandle]
The z-axis is very simple to model:
private Dictionary<int, int[]> zAxis = new Dictionary<int,int[]>();
This implementation of a Pile space works pretty well as a proof-of-concept. To become production ready, though, many things have to be improved. No thread-safety yet, no persistence yet, no transactions, no security yet, no deletions yet etc. Also the data structures need to become more efficient; currently lots of RAM is needed to hold all the relations for a simple text. But that´s all a matter of optimization. My concern for now just was to show (myself), how a Pile engine in general could work.
Now, that I know, for many improvements it will be sufficient to change just the implementation of the Pile space engine. As long as no changes to the interface are needed, layers on top of it will not be affected. (In fact I alreads implemented a second Pile space engine which replaced all in-memory data structures with simple database tables. It used the table-oriented API of VistaDb, a nice small SQL database. Unfortunately, though, this implementation of a persistent Pile space engine was very naive and had very poor performance. However, it showed at least, how easy it is, to replace on Pile space engine implementation with another. Since then, though, I´ve learned a bit about how a Pile space can be partitioned as to be able to swap in and out smaller pieces. But that´s maybe a topic of another posting...)
A prototype Pile engine
The layer above the Pile space engine knows about relations and manners. It also knows about parents and children and Terminal values. Most of the methods of the Pile engine, though, are very thin and just more of less delegate their work to the Pile space engine. The so to speak just translate between terminologies, from relations to Pile space and back.
namespace pile.engine32
{
public class PileEngine
{
public class ParentRelations
{
private int nParent, aParent;
internal ParentRelations(int nParent, int aParent)
{
this.nParent = nParent;
this.aParent = aParent;
}
public int NormativeParent
{
get
{
return nParent;
}
}
public int AssociativeParent
{
get
{
return aParent;
}
}
}
public int CreateTop()...
public ParentRelations GetParentRelations(int childRelation)...
public int GetChildRelation(int normativeParentRelation, int associativeParentRelation)...
public byte GetRelationQualifier(int relation)...
public int CreateChildRelation(int normativeParentRelation, int associativeParentRelation, byte qualifier)...
public int CreateChildRelation(int normativeParentRelation, int associativeParentRelation, byte qualifier, out bool childAlreadyExisted)...
public int[] FindNormativeChildRelations(int normativeParentRelation)...
public int[] FindNormativeChildRelations(int normativeParentRelation, byte qualifier)...
public int[] FindNormativeChildRelations(int normativeParentRelation, byte qualifierFrom, byte qualifierTo)...
public int[] FindAssociatveChildRelations(int associativeParentRelation)...
public int[] FindAssociatveChildRelations(int associativeParentRelation, byte qualifier)...
public int[] FindAssociatveChildRelations(int associativeParentRelation, byte qualifierFrom, byte qualifierTo)...
}
}
CreateTop() returns a relation without parents. It´s called by a Pile agent to create a representation for a Terminal value or to create a System Definer. The Pile agent needs to keep track of which handle belongs to which Tv.
CreateChildRelation() on the other hand creates a new relation from two parent relations. Because two particular parent relations can only be related once by a child relation, the method returns this child relation if both parents should have been associated before:
public int CreateChildRelation(int normativeParentRelation, int associativeParentRelation, byte qualifier, out bool childAlreadyExisted)
{
int h = phs.GetHandleByCoordinates(normativeParentRelation, associativeParentRelation);
if (h == 0)
{
h = phs.CreateHandle(qualifier);
phs.SetHandle(normativeParentRelation, associativeParentRelation, h);
childAlreadyExisted = false;
}
else
childAlreadyExisted = true;
return h;
}
The method first checks, if the child relation already exists. If not, it creates a new handle for it and stores it at the coordinates of the parent relations.
GetChildRelation() returns the child relation of both parents - or 0 if it does not exist.
GetRelationQualifier() extracts the Qualifier from a relation´s handle.
Find...ChildRelations() returns an array of relations in the specified manner and optionally matching the Qualifiers passed in. The Find...() methods are important when searching in a Pile, because often many relations need to be traversed to check, if the lead to the relation looked for.
A prototype full text search Pile agent
The Pile agent sits on top of the Pile engine and implements a domain specific solution: search for patterns in plain text files. Only the Pile agent knows, which System Definers, Terminal values and Qualifiers are needed. Usage of the PileAgent class whose methods you see below is very simple. To load texts into the Pile call one of the StoreText() methods:
PileAgent pa = new PileAgent();
int tFox = pa.StoreText("The quick brown fox\r\njumps over the lazy dog.");
int tPeter = pa.StoreText("Peter Piper\r\npicked a pack\r\nof pickled peppers.");
Pile calls loading data into a Pile assimilating it. It kinda gets "sucked in" and "shreddered" and so to speak looses its identity. You can´t see it anymore as one unit of data. There are only relations of which some are new and other have existed before. But be assured, you can retrieve the text from the Pile, anytime you want :-) What is retrieved, though, is not the original text, but something that looks exactly like it. The text you get back is generated from the associtations in the Pile like a picture in a computer game is generated from an internal model of the game´s world.
For the Pile agent call one of the Retrieve...() methods. For an assimilated text pass in the handle you got back from StoreText():
Console.WriteLine(pa.RetrieveText(tFox));
Of course the purpose of a full text search Pile agent is searching for patterns and returning all texts containing it. To do this, call FindTexts() and get only the lines with the pattern generated:
TextFound[] tf = pa.FindTexts("peter", false);
foreach(TextFound t in tf)
foreach(int l in t.LinesHandles)
Console.WriteLine(pa.RetrieveLine(l));
A TextFound instance represents one texts in which the pattern was found with all the lines containing it. Text as well as lines are returned as relation handles.
This is a minimal API for a full text search Pile agent. No methods to delete texts, no methods to enumerate the contents of the Pile, no persistence. But for loading texts and searching them it´s ok. Here´s the list of all public (and some private) methods:
public int StoreText(System.IO.TextReader tr)...
public int StoreText(string text)...
private int StoreLine(string text)...
public string RetrieveText(int handleOfText)...
public string RetrieveLine(int handleOfLine)...
private System.Text.StringBuilder ConstructLine(int handle)...
private void ConstructStringFromRelations(System.Text.StringBuilder sb, int handle)...
public class TextFound
{
...
public int TextHandle...
public int[] LineHandles...
}
public TextFound[] FindTexts(string pattern, bool caseSensitiveComparison)...
If you want to try the Pile prototype application now, download it (it´s an updated version), assimilate some texts, and check out how long it takes to search for patterns of several sizes. You can find suitable texts at Project Gutenberg (e.g. Hamlet, MacBeth, King James Bible (4.5 MB), or The Koran (1,44 MB)) or take the RFC of your choice (e.g. HTML, or SMTP).
Text representation
You now know how to use the Pile agent. But you sure are also interested in how it works and uses the Pile engine. So let me start with how texts are represented in the Pile.
As Terminal values I´ve chosen the well known basic 256 characters. For each the Pile agent creates a Top as well as a Root. The Roots, so to speak, are the representations of the Tops within a specific context. This context is spanned by a System Definer.
The Pile agent has two System Definers: One to keep track of assimilated texts, one for the low level representation of text lines. (I´m not satisfied with this implementation anymore, though. But it works :-) So I leave it as is for now.)
Even though when implementing the Pile agent I did not define a formal schema, you can think of it like this:
Composit Relations:
FullTextPile ::= { Text } .
Text ::= { line } .
Value Relations and Terminal values:
line ::= { letter } .
letter ::= "A" | "B" | ... | "a" | "b" | ... .
The "mesh of relations" then consists of three parts:
- There are the Terminal values outside the Pile with their internal representations, the Tops.
- There are Roots and the relations built on top of them to represent individual lines of text. Their tree starts at the sdLetterRoots System Definer.
- There are the relations for texts and lines starting at the sdText System Definer.
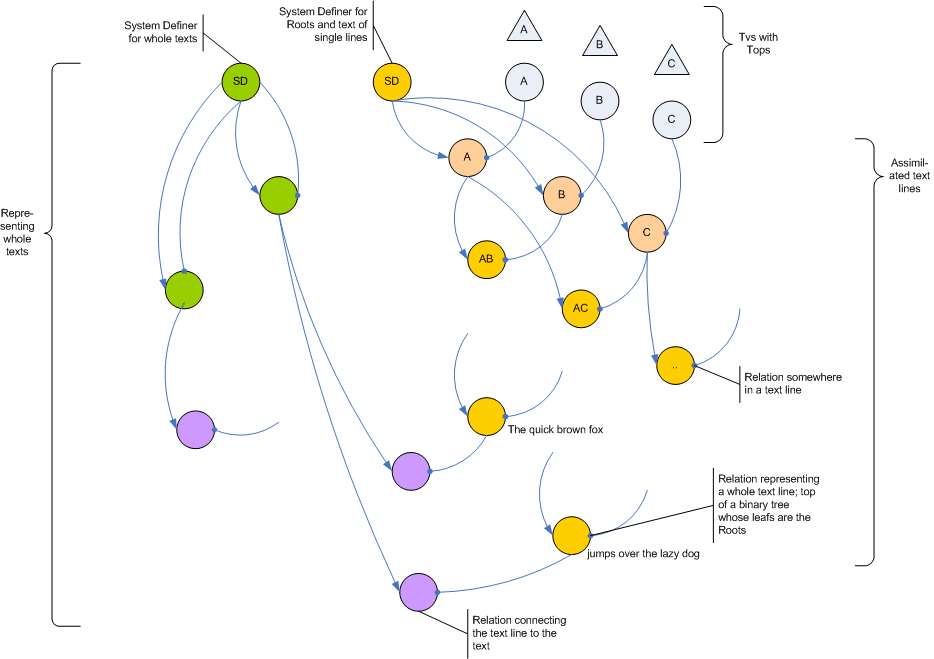
As you can see, there are two "logics" or contexts or systems in one Pile. One system concerned with handling raw texts lines represented by a single relation on top of a binary tree. And one system concerned with managing texts and lines - and connecting those lines to the text line relations in the other system. The purple relations in the above picture so to speak are transcending the text logic to reach into the basic letter logic.
Retrieving text
To retrieve text from the above associative structure is easy. If you have a handle of a text or line in your hand, you just recursively traverse the tree of relations down to the Roots or Tops and assemble it letter by letter. See ConstructStringFromRelations(), it´s just some 15 lines of code. Very easy. RetrieveLine() and RetrieveText() build on top of this method.
Storing text
Storing text or assimilating it into the Pile is a little more difficult, but still straightforward. StoreLine() does it in some 50 lines of code. StoreText() builds on it and just splits the text to store into individual lines and binds together the assimilated lines under a relation for the whole text. Since there is no order in the texts, all text relations have the sdTexts System Definer as their normative as well as associative parent.
StoreLine() first creates relations for pairs of letters in the line. For "The quick brown fox" this would be:
Th=("T", "h")
e_=("e", "_")
qu=("q", "u")
ic=("i", "c")
etc.
Then it creates relations for pairs of those relations, e.g.
The_=(Th, e_)
quic=(qu, ic)
etc.
This process of pairing is continued, until only one relation representing the whole text line is reached. It´s the top of a binary tree and is returned from StoreLine() to be connected to the relation representing the whole text.
Two things are to note here:
- If a relation already exists, e.g. Th or quic, because it has been created while assimilating some other text, it is reused!
- Representing a letter of 1 byte with a handle of 4 bytes and connecting two letters with a relation resulting in 12 bytes (for all three handles) sounds like wasting space. But in fact in the long run space is saved. Consider the King James Bible: It´s some 4.5 million bytes, but requires only some 800,000 relations amouting to some 3.2 million bytes. Even though the prototype Pile application uses up much more space, this example should show, using relations is not per se wasting precious bytes.
Searching for text
Search for patterns in the assimilated texts certainly is the most difficult part of the Pile agent. It took me some 200 lines of code and a couple of days to get it right (or to be precise: almost right ;-) FindTexts() works pretty well, but is not error free yet). A detailed description I´ll leave for some other time, but to get you started in analysing my code, let me explain the basic approach, which is characteristic for Pile applications:
When searching for a pattern, e.g. "the", you start at the bottom of the binary trees representing the texts. That means, you start at the Roots of the system.
The algorithm of FindTexts() can be sketched like this:
- Set up a list of relations for the characters in the pattern for look for. That means, find the Root for the letters "t", "h", and "e". The list is called followers.
- Take the first relation and move it to a list of firsts.
While searching, the pattern is split in two parts: On the left are the relations already found matching the first n letters of the pattern, e.g. the relation th, since "th" has already been found. On the right are the remaining letters that still need to be matched and which follow the first letters, e.g. "e".
firsts needs to be a list, since there might be many locations in a Pile, where a sub pattern occurs, e.g. many lines in which "th" is present. And each of these locations has to be checked, if it also matches the following character.
With firsts and followers in hand...
Repeat as long as there are follower characters
Repeat for each relation in firsts
Get the next follower
Find a path from the current firsts´ relation to the follower
If there exists such a path, then remember the relations at the top of this path and add them to the firsts list for the next round
The difficult part is "Find a path". This really made me scratch my head a lot. You´ll find my solution in the method SearchValley(). The algorithm is called valley search since you start from some relation closer to the roots, wander the binary tree of relations within a line down closer to the top, then wander it up again to the roots.
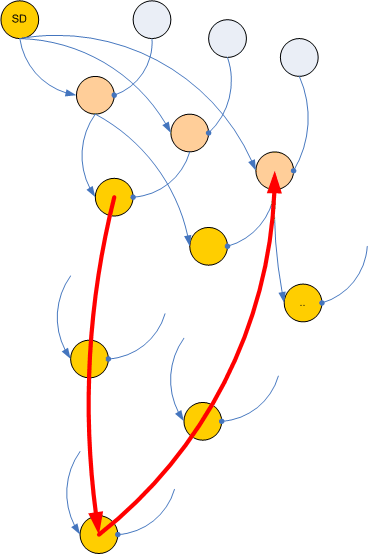
You see the "valley" in the picture: the red arrows sketching the search path are going down and up again, like through a valley.
This Valley Search is not so easy, because you need to consider going down relations along the associative and then normative manner and then going back up along the associative and then normative manner. If there was just one line of text and one location for a pattern within this line, then all would be pretty easy. But many locations in many lines... you really need to keep track in your algorithm of where you are, which path you follow. Recursion helps, though :-)
But let the details of the search algorithm not deter you from the basic search paradigm: When searching in a Pile you start at the Roots! That´s the fundamental insight you should take away from here.
Download
You can download the prototype Pile application from my website here. Check it out, toy around with it. I hope you find your way around in my code. I at least tried to structure it so it makes sense to you.
You need Microsoft Visual Studio 2005 (!) for it to compile. But I guess the express edition, which is very cheap or altogether free, will do.
Let me know what you think, if you like.
I guess, this will be the last posting on Pile for a while. I need to learn more about it. I need to move on to other projects I unduely neglected because I´m so infatuated with Pile ;-) But after having written all this I now kinda feel relieved.