Musings on relations - or: WinFS is not enough
Have you had a look at WinFS? No, you should. It´s cool. Or maybe I should say: It could be even more cool, if it didn´t stop too early.
The basic idea behind WinFS is: set your data free! Unlock the gems hidden in large databases! Microsoft´s fundamental insight underlying this is, the future is about relationships between data and you can only set up relationships between separately adressable and accessable units of data.
Within a single relational database you can setup relations between rows in tables. The relationship between smaller informational units (columns, fields) is implicit by arranging them within a single table. But what about relationships between data in different databases? Although that´s possible, it´s not really what you want to do in your day to day business. Databases thus draw a boundary around data. From a security point of view this is of course benefical; but from a data reuse point of view, this is a contraproductive.
Wouldn´t is be nice, though, to not be concerned about the database, the bucket where an address is stored in? Wouldn´t it be nice to be able to relate an existing address to a new information you want to store, which not necessarily comes to rest in the same database as the address? Think about linking your latest digital pictures to contacts you already have in Outlook. Think about adding tasks in Outlook to an order workflow process in your ERP program.
All those scenarios are either not possible today or very hard to achieve. That´s the reasoning behind why WinFS is needed. With WinFS there is no more Outlook .pst file hiding all those precious contacts, tasks, emails and appointments behind a wall. Instead these items are set free to float around as separately addressable and accessable data units in the file system space. And you can do the same with your own data.
Once there are comparatively small data items floating around rather than being penned up in an ever increasing number of (incompatible) databases, you can start to relate those data items to each other. That´s so cool! It let´s you reuse information in different contexts/programs instead of reentering (or importing/exporting) it over and over again.
However, although WinFS breaks up the database barriers around the information nuggets it remains in the world of relational databases. No, not just because SQL Server 2005 is the foundation on which WinFS is built. Rather because relationships are still an afterthought and a second class citizen in data modelling.
From data to associations
Filesystems, XML, RDBMS, ODBMS and also WinFS are all data centric. Data is the main concern. Storing data is the most important task of an RDBMS. Databases are about recording data, making it persistent. Well, that sounds reasonable, doesn´t it?
The following picture depicts the current thinking: Data is arranged in fields stuffed into a row. Rows can point at each other. The data items (fields) are related implicitly and explicitly on two levels: implicitly by putting them next to each other in a row and storing all rows of the same kind in a table, explicitly by foreign keys.
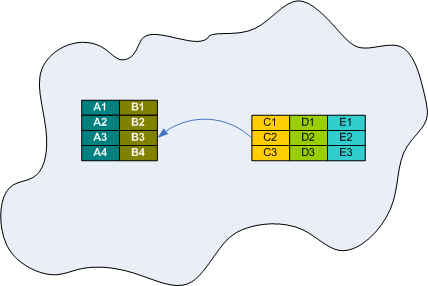
The relational calculus is good in describing sets. But it´s bad at describing relations between data in different sets. Explicit identities (primary keys) need to be introduced and normalization is needed to avoid update inconsistencies due to duplication of data.
To say it somewhat bluntly: The problem with the relational calculus and RDBMS etc. is the focus on data. It´s seems to be so important to store the data, that connecting the data moves to the background.
That might be close to how we store filled in paper forms. But it´s so unlike how the mind works.
There is no data stored in your brain. If you look at the fridge in your kitchen, there is no tiny fridge created in your brain so you can take the memory of your fridge with you, when you leave your kitchen.
Instead the fridge is left where it is, right there in your kitchen. However, what is stored in your brain are associations of all kinds. In fact, your brain can only store "immaterial" associations. (Let´s neglect for the moment, that those immaterial associations need to manifest themselves somehow, e.g. electrical signals, chemical substances, or cell growth.)
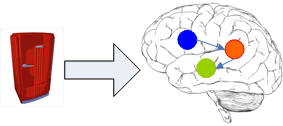
The fridge causes the brain to setup internally an unknown number of associations. Thus, the brain works just with relations/associations and not with data or "the real things". The brain has its own representations for the data. There is not data in the brain; rather the data itself stays outside the brain.
So "the real thing", the fridge, is not in the brain, but instead some kind of, hm, "token" or handle. Or maybe there is not even a "token" for a whole fridge in the brain, but a large number of handles for parts of a fridge? Or what seems to be even more likely: the brain knows nothing about fridges and fridge parts, but just about very, very simple visual structures like points, edges, colors. So the mental representation of a fridge is a set of relations between such basic structures/concepts. Then the brain does not need "tokens" for real world entities, but just for basic structures/concepts to relate them to each other.
Ok, why am I telling you all this? What does this have to do with WinFS? Well, it´s about a completely different way to deal with data (or things). To map what the brain does to the software world means, removing the data from the "system" leaving only associations:
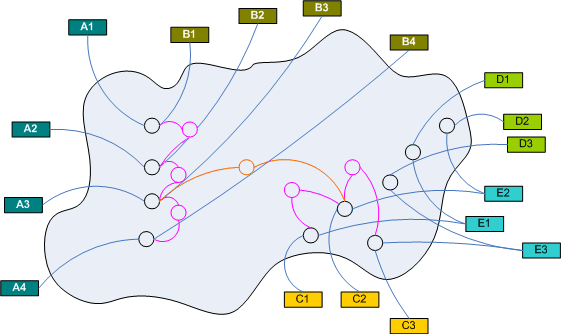
Within the "system" there are just associations and associations between associations. The data is outside the "system". Compared to our traditional thinking this kind of "system" is homogeneous. There are only associations. That´s it. The is no distinction between associations and data or different kinds of associations (implicit vs explicit). Associations or relations are first class citizens in this kind of "system".
And since there are no different kinds of data and no more "data buckets" like tables or columns, any association can be associated with any other association.
When you define an RDBMS schema you explicitly set up which kind of data (rows) can be connected to which other kind of data. You try to forsee what could possibly make sense in terms of associating data. Well, that´s what the Outlook team did in the past. They said: Well, we think, users want to associate a contact with an appointment or an email with a task. So we stuff everything in a nice little database.
But then, users thought differently. All of a sudden, they wanted to associate an Outlook contact with an invoice - without success, because the Outlook developers had thought they could foresee the future usage of certain data.
This dawned on Microsoft and they now come up with WinFS. Great! Or not?
No, not so great, although still technologically cool. Because WinFS still requires you to think in pretty large bins of data (e.g. a contact, an appointment). Although you can set up relations between those smaller bins, WinFS still is about data first - and only then come associations between data. It´s a heterogeneous system.
Your brain, on the other side, is homogeneous: the brain knows only about associations. Because that´s the only way to deal with an unpredictable world where you cannot foresee how "things" might look and behave and how you might want to associate fine grained basic concepts like points or coarse grained concepts like fridges with each other. The brain knows about causality/time, points, edges, space, that´s probably pretty much it. Those concepts/structures are its roots. All else is just associations between those roots and other associations. Billions, trillions of them. And it works :-)
So why stop where WinFS stops? Why not take WinFS to the max? Why not radically chance of view of the database world? How about association bases or connection bases instead of data bases?
A world of associations
The gain of a new view on how to deal with data would be an explosion of possible associations. When you look at your fridge, you immediately can see it in different contexts: there is the context of "kitchen" where the fridge is one of many applicances, then there is the fridge as a manufactured product pointing to a history of industrial production, then there is the context of "food" which the fridge keeps, then there is the context of "information" because you put post-it! notes on the fridge´s door, and so on...
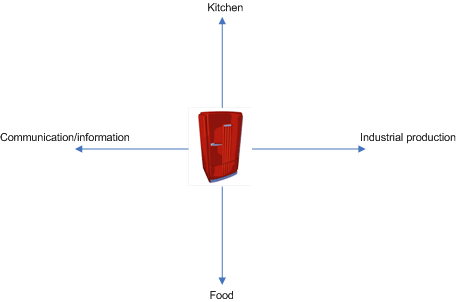
The fridge is at the origin of a multi-dimensional space of contexts. Many different contexts intersect in a fridge. That´s so natural to all of us... so why not treat data the same?
Switching to a new view on dealing with data is thus a switch from one context to multiple contexts. In an associative system and data unit (external to the system) can exist in any number of contexts, just depending on the associations between it and other data units or other associations.
So if associations are the real value of data, because they put them "in perspective" aka into different contexts, then how to get more out of an associative system? Well, by forming as many associations as possible (or as makes sense for a certain observer).
Since the number of possible associations is determined by the number of data units, it´s best to see to maximize their number first. And that´s exactly where WinFS falls short.
Although WinFS promotes disassembling databases into their rows (objects, e.g. contacts, tasks), the resulting data units not only stay within the system, but are also still fairly coarse grained. A whole contact can be associated with a whole appointment.
But why stop there? Why disassemble the data further in order to be able to generate even more associations? Who´s able to foresee that associating a whole task with a whole invoice is all that users ever need?
Maybe I want to navigate (by traversing the maze of associations) from a single date in an appointment to contacts with this date as a birthdate? Why not reuse names from contacts in the context of appointments? And I mean just names.
What this would mean is blowing up those WinFS data units (objects) into very small pieces, data atoms. Each atom being some data unit which cannot be split into smaller pieces.
Single letters come to mind as candidates for a data atom. (The bit values 1 and 0 would be the true data atoms, but even though it would be possible to build a "system" on them, since letters are just associations between 1s and 0s, I find this low level a bit unwieldy.) Pictures might be larger data atoms because their individual bytes might indeed make no sense in other associations - but who knows.
In the end, an associative base system should be data atom agnostic. If might know, data atoms are streams of bytes and might offer to store them as is. But then... why should it know about data atoms? They are of no use within (!) the system. So an associative system should provide just one operation concerning data atoms: create a handle for a data atom, if you ask it to.
The associative system then looks like this:
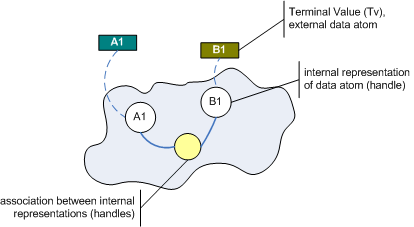
Whatever is outside the system, the system does not care about. However, in order to setup associations with the outside data atoms, the system has to have some kind of internal representation, that´s why the system needs to be able to generate - ex nihilo so to speak - handles for external data atoms (or terminal values). What those handles mean, which terminal values they stand for, whether it´s a single letter or a multi-megabyte picture, the associative system does not know.
Conclusion
Now, think about the implications for a while...
Such kind of associative base, an AB instead of a DB if you want, would not store data, but rather would generate data from data atoms as needed.
Take a text like the Bible: If you defined the 256 ASCII characters as to be the atoms, then there would be no bible text data, but just some 800,000 associations between those 256 terminal values and other associations. (I know this figure, because I´ve implemented such a system in C# and loaded the 4.5 MB King James Bible into the AB.)
Still, though, I can losslessly generate the complete Bible text upon request from those associations. It´s just a matter of recursive descend in a binary tree. But what´s more important is, no combination of letters would need to be stored twice in such an AB. Each association could be unique. No more duplication of data.
This, though, not only leads to maybe saving some disk space, but it means, when looking for the pattern "Enoch" I immediately get all contexts in which Enoch appears in the Old Testament. Starting to look for patterns from the handles for their terminal values immediately leads to all associations which connect to those patterns.
But this is only a simple example and you might say, hey, this is what full text database searches are for. And you´re right! However, a full text database stores the data twice: once as the data, and once all the major words in the index. Also a full text database usually limits you to searching for words. If you want to look for arbitrary patterns, e.g. "o b" in the text of Hamlet, then you´re lost. A full text search engine would not return "to be". For an AB engine, though, this would make no difference. And that´s important, for example, in searching for gene sequences in the field of bio informatics.
I can understand, though, if you find it difficult to switch your thinking from data centric to associations only. It took me 2-3 weeks and I´m still working on it. But the potential of this switch seems to be huge! Each day I learn something new. It almost feels as if I´m in love :-) I´m almost blocked from doing other work, because my mind reels with the possibilities and implications. That´s the reason, why I needed to write this blog entry. I needed to get this out of my head to move on.
Just yesterday I talked to a developer of an ODBMS about all this. Fortunately I was able to depict all this to him on the phone - and he immediately grasped the idea. He even corrected me when I thought about maybe defining whole data fields (e.g. a name, a birthdate, a zip-code) as data atoms to gain performance from having a "regular" database engine to index them. He said, no, that´s not necessary, because all those values (consisting of characters) can be indexes using associations within (!) the AB. And he´s right! I felt so relieved: Such an index would be just another context in with terminal values appear.
The beauty of an association only system is very striking, I think. So while WinFS is a cool idead compared to todays situation, WinFS is but a small step towards really setting data free to be associated in a million ways like in our brains.