Drill down on the communication between application and resources - Bonus: The reporting puzzle solved
Yesterday I drilled down into my new view on application architecture to explain, how I think frontends and application should communicate.
Today I want to drill down on the relationship between application and resources. (For the relationship between applications consult the SOA literature.)
To do their work, applications rely on services provided by resource components. Resources are passive, in that they don´t demand functionality from the application. Frontends on the other hand are active, as they trigger application functionality.
Resources are about data. Which does not mean, they are necessarily concerned with databases. A resource could, for example, be a source of random numbers generated by some hardware attached to a computer.
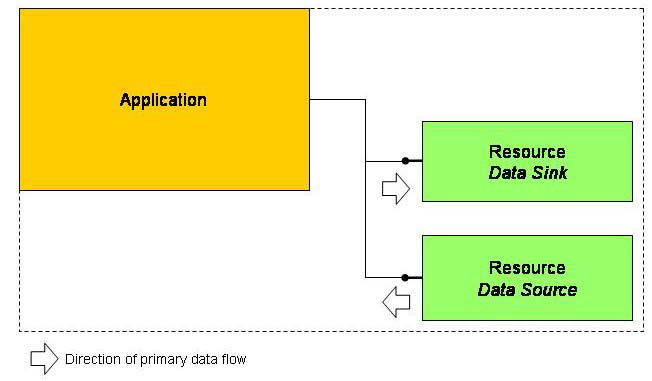
Applications need data resources for their work. Resources live close to an application and can be classified as data sources or sinks.
Resources can be categorized as data sinks or data sources or they serve as both.
But regardless, their services should be offered thru an interface facade. On the outside, resources thus look like applications. This again fosters decoupling etc.
However, resources are typically not living on their own. They are not applications, but rather helping applications by living close to them, i.e. usually within their process. From this follows, the data flow between application and resources does not necessarily be in a disconnected manner. There can be streams between applications and resources (while some application message endpoint triggered by some frontend is doing its work).
Nonetheless it´s advantageous to model the outside of resources with interfaces. But those interfaces can function as factories for deep object hierarchies connected to the resource. I think, that´s perfectly ok. But if you like, sure you can work with resources in a disconnected way using disconnected data containers to move data back and forth.
A resource component itself usually has the following structure:
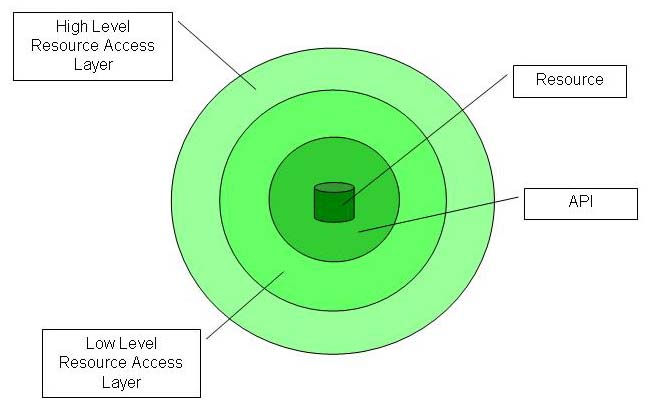
Usual structure of a resource.
A resource component encapsulates a resource. This can be a database, a TCP/IP connection, a RS232 interface, a file, a process controller etc.
The resource component uses the resource thru an API. This can be ADO.NET, System.Net, System.IO etc.
Now, the important part about resource components is, an application does not use the API directly, but rather a higher abstraction. However, by that I don´t mean a generic data access layer around ADO.NET (like the data access building block), which I call "Low Level Resource Access Layer" (LLRAL). Such a LLRAL is nice to have when implementing a resource component, but by no means necessary.
Necessary, though, I think is an interface providing access to the resource in terms of the problem domain of the application. If the application is about order entry, then a resource component encapsulating the database should for example provide an interface with a method called GetOrdersOfCustomer(). In the case of database resources, the resource component should abstract away the resource, so that there are no more SQL statements in the application.
Where the LLRAL is nice to have, the High Level Resource Access Layer (HLRAL) is a must!
That said, now for a special case of a resource, that boggled my mind for quite some time. I´m talking about streams of data.
When trying to convince developers to use DataSets they mostly nod and they "Sounds nice, but...". And they mean: But what about use cases where I need to work with streams of data, where I need to work with millions of records in a database? And they have a point there.
But now I feel I have the answer:
- Streams of data between frontends and application are always "evil". Don´t do it. Ever! Forget about displaying three million records in a WinForms DataGrid. Always use disconnected data containers!
- But streams of data are perfectly fine between application and resources! So if you like, go ahead an open a ADO classic Recordset by calling a resource component method. Move up and down the cursor as you like - within the call stack originating from a single method call on an interface of an application. As long as you´re in this call stack, the application logic is stateful and all´s just fine.
And if working on those three million records takes longer than a second, do the processing asynchronously within the application.
Sounds easy, right? But then, what about reporting? And this is, why sticking with this answer had been difficult for me. Reports often work on huge amounts of data. And reporting engines are frontends or are used in frontends. So they´d need streaming access to data. Right?
But giving reports streaming access to data is against the programming paradigm of applications described so far.
Firstly, because all data transport should be using containers. Secondly, if reports circumvent the application and directly access a data source, no business logic gets enforced. Both is bad.
The solution to this came to me yesterday morning: Our current view of how reporting should work is wrong. Crystal Reports and even the new SQL Server Reporting Services are based on direct access to the data they report on. They pull the data they need from the data source. And that´s not good. No, no, not good at all!
Rather than allowing reporting engines to pull data from resources, we should push the data to them. And that´s the responsibility of the application.
Reporting in the future thus should look like this:
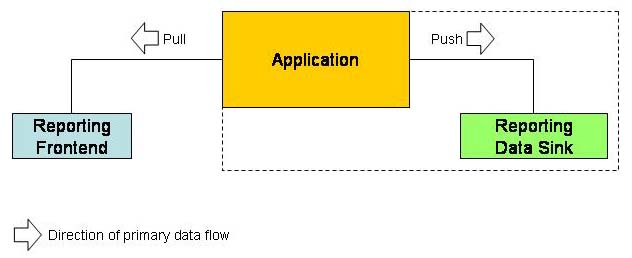
Either a reporting engine is capable of pulling data from our application, thereby following all our business rules. Then reporting on the frontend is just fine - but it is limited by how much data can be packed into a data container.
Or, and this is the solution to the sceptical throwns of the above developers, or a frontend triggers the application to produce the report (maybe asynchronously). The application then pushes the data to report on to some reporting engine data sink. The application could, for example, open a ADO.NET DataReader based on a complex SQL Join, and pass each record to the reporting data sink in a generic name-value data container or via a TCP/IP connection. At this point, we don´t need to care how this happens, whether the application gets some help from the report engine or not. Most important is, the application pushes (!) the data to the reporting engine. Then, how the reporting engine processes the data or on which computer it is located, is not important either at this point.
So this is my message:
Whenever you think you need streaming access to data, only think of doing it within the application, never in the frontend! And if this streaming access so far pulled the data itself from a resource, think about switching to a push model, where the application sends the data to your processing logic. Rather than a frontend implement a resource component.