Recoverability with Azure Functions - Delayed Retries
In the previous post, I showed how to implement basic recoverability with Azure Functions and Service Bus. In this post, I'm going to expand on the idea and demonstrate how to implement a back-off strategy.
Back-off strategy
A backoff strategy is intended to help with intermittent failures when immediate subsequent retries will suffice due to the required resources not being available within a short period but having a high probability of being back online after a short timeout. This is also known as delayed retries, when retries are attempted after a certain time (delay) to increase the chances of succeeding rather than bombarding with immediate retries and risking failing all the attempts within a short period.
Implementation
For delayed retries, we'll set an arbitrary number. Let's call it NumberOfDelayedRetries. The number could be hardcoded or taken from the configuration. The idea is to represent with this number how many delayed retry attempts there will be. Setting it to 0 would disable delayed retries altogether.
Delayed retries should kick in when the immediate retries are all exhausted. With Azure Service Bus, immediate retries are fairly simple to implement - Service Bus does that for us with the DeliveryCount on the given message. Unfortunately, today, there's no way to achieve the same with the native message. This will change in the future when there will be the ability to abandon a message with a custom timespan. Until then, some custom code will be required to mimic this behaviour.
Delayed retry logic
Whenever all immediate retries are exhausted, a message should go back to the queue and be delayed (scheduled) for a later time to be received. The problem with this approach is that we could exceed the MaxDeliveryCount that's there to protect from infinite processing. Sending back the same message also won't work due to the reason explained above (service limitation). So we'll cheat.
The incoming failing message will be cloned. And when cloned, we'll add a header, let's say "Error.DelayedRetries". And each time we want to increase the number of attempted delayed retries, we'll read the original incoming message's header and increase it by one for the cloned message. The first time, there will be no such header, so we need to account for that. As long as we need to proceed with the delayed retries, we'll be completing the original incoming message. That's why logging at this point is important.
public async Task Invoke(FunctionContext context, FunctionExecutionDelegate next)
{
try
{
await next(context);
}
catch (AggregateException exception)
{
BindingMetadata meta = context.FunctionDefinition.InputBindings.FirstOrDefault(b => b.Value.Type == "serviceBusTrigger").Value;
var input = await context.BindInputAsync<ServiceBusReceivedMessage>(meta);
var message = input.Value ?? throw new Exception($"Failed to send message to error queue, message was null. Original exception: {exception.Message}", exception);
if (message.DeliveryCount <= 5)
{
logger.LogDebug("Failed processing message {MessageId} after {Attempt} time, will retry", message.MessageId, message.DeliveryCount);
throw;
}
#region Delayed Retries
var retries = message.GetNumberOfAttemptedDelayedRetries();
if (retries < NumberOfDelayedRetries)
{
var retriedMessage = message.CloneForDelayedRetry(retries + 1);
await using var senderRetries = serviceBusClient.CreateSenderFor(Enum.Parse<Endpoint>(context.FunctionDefinition.Name));
await senderRetries.ScheduleMessageAsync(retriedMessage, DateTimeOffset.UtcNow.Add(DelayedRetryBackoff));
logger.LogWarning("Message ID {MessageId} failed all immediate retries. Will perform a delayed retry #{Attempt} in {Time}", message.MessageId, retries + 1, DelayedRetryBackoff);
return;
}
#endregion
// TODO: remove when fixed https://github.com/Azure/azure-functions-dotnet-worker/issues/993
var specificException = GetSpecificException(exception);
var failedMessage = message.CloneForError(context.FunctionDefinition.Name, specificException);
var sender = serviceBusClient.CreateSenderFor(Endpoint.Error);
await sender.SendMessageAsync(failedMessage);
logger.LogError("Message ID {MessageId} failed processing and was moved to the error queue", message.MessageId);
}
}
And that's all there is. The extension methods GetNumberOfAttemptedDelayedRetries() and CloneForDelayedRetry() are provided below for reference.
public static int GetNumberOfAttemptedDelayedRetries(this ServiceBusReceivedMessage message)
{
message.ApplicationProperties.TryGetValue("Error.DelayedRetries", out object? delayedRetries);
return delayedRetries is null ? 0 : (int)delayedRetries;
}
public static ServiceBusMessage CloneForDelayedRetry(this ServiceBusReceivedMessage message, int attemptedDelayedRetries)
{
message.ApplicationProperties.TryGetValue("Error.OriginalMessageId", out var value);
var originalMessageId = value is null ? message.MessageId : value.ToString();
var error = new ServiceBusMessage(message)
{
ApplicationProperties =
{
["Error.DelayedRetries"] = attemptedDelayedRetries,
["Error.OriginalMessageId"] = originalMessageId
},
// TODO: remove when https://github.com/Azure/azure-sdk-for-net/issues/38875 is addressed
TimeToLive = TimeSpan.MaxValue
};
return error;
}
Notice the "Error.OriginalMessageId" header. It is helpful to correlate the original Service Bus message to the delayed retried messages as those are physically different messages.
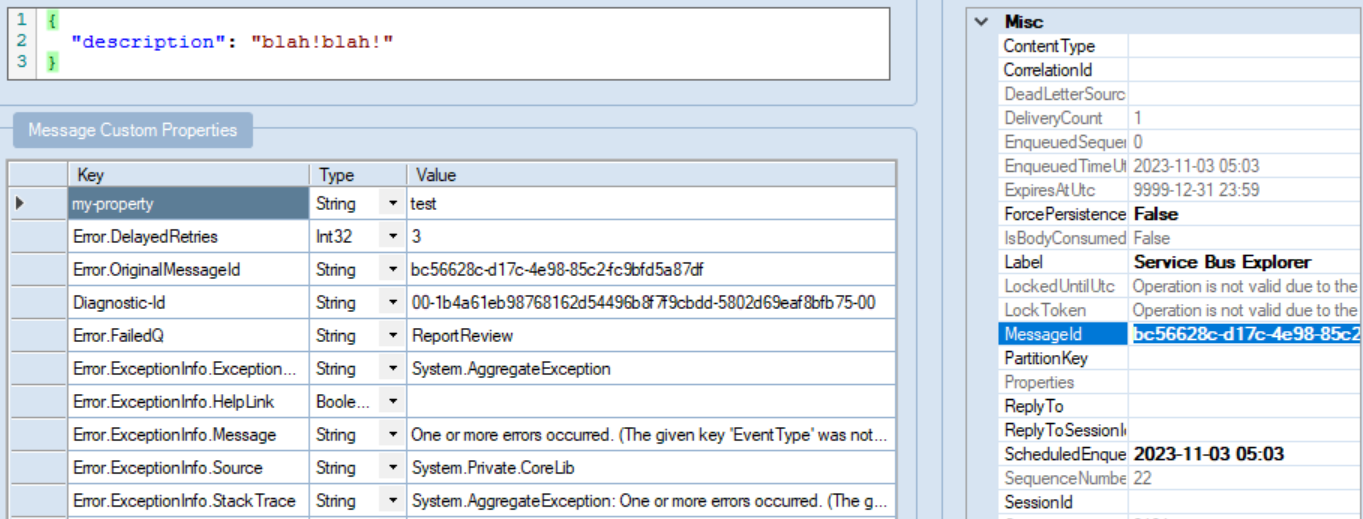
Et voilà! We've got ourselves a nice recoverability with immediate and delayed retries to help deal with intermittent errors and temporary failures.

Auditing
In the next post, I'll demonstrate how we can implement the audit trail of the successfully processed messages to complete the entire picture of all messages processed with Azure Functions.