NSimpleDB - Use Amazon´s SimpleDB data model in your applications now - Part 1
Have you heard about Amazon´s online "database service" SimpleDB? They describe it like this: "Amazon SimpleDB is a web service for running queries on structured data in real time." So it´s not a RDBMS, because Amazon does not call the data "relational", but just "structured". And you use a web service based API to access the data, not good old ADO.NET. Currently SimpleDB is in beta. You can get a test account to play around with it - if you´re patient. As of this writing (Jan 08) evaluation is limited; you need to apply and queue up to be assigned a test account. I have about 2 weeks ago, but haven´t heard from Amazon since then.
But why should you care? Well, SimpleDB would allow you to store data in a database without any setup costs. You don´t have to care about backup or moving to another ISP. You´re data, lots of data, can just stay with Amazon. Just add a web service proxy to you web (or desktop) application and off you go. This certainly make some (or a lot, or at least a growing number of) applications easier to implement.
Another reason to care about Amazon´s SimpleDB is its simplicity. In an age where dynamic programming becomes ever more popular and static whatever (e.g. typing, binding) loses value, making persistence more dynamic sure should look attractive. But exactly this is what Amazon´s SimpleDB is about: highly dynamic persistence of structured data.
SimpleDB data model
With SimpleDB you don´t define a database schema anymore. Your "data space" with Amazon is structured in a very simple way: it´s devided into sub-spaces called "domains" which each contain so called "items" which each contain so called "attributes". That´s it. And you can change the structure of this "data space" at any time. There is no distinction between meta data and data. Creating a domain (which resembles a table in a relational database) is a web service operation like storing an item in a domain.
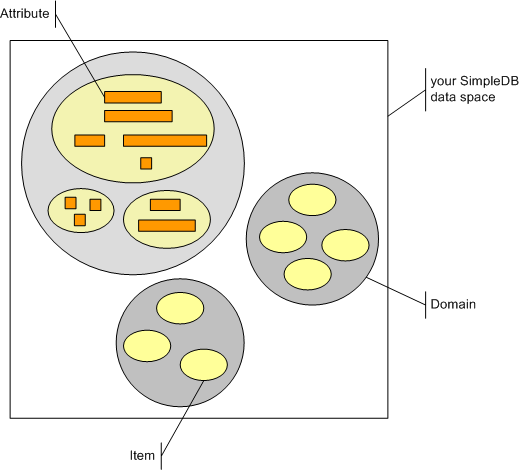
To make it very clear: You divide your "data space" into domains at your leisure. (Amazon currently just artificially limits the number of domains to 100.) And you stuff items of any structure into these domains. You never define a schema for a domain. The items stored in a domain don´t have to look the same. They can contain any number of attributes; all can differ in their number of attributes.
Attributes are name-value-pairs. So items are tuples of arbitrary aritiy. That means, SimpleDB is not a relational database, but a tuplespace. Just throw items/tuples into your SimpleDB instance at your leisure. That´s all their is to SimpleDB persistence. If you like, separate tuples into different domains - but if you do it or not does not make a big difference. For distinguishing between, say, customers and invoices that´s not necessary. It might even be contraproductive, since querying items is limited to one domain at a time. There is no such thing as a SQL Join.
The use of domains
So why are there domains at all? Probably they help Amazon to make replication of items between servers easier. And it might speed up queries if you distribute your data across domains. So think of domains as easy to set up data partitions in case you have to deal with huge amounts of data.
Multi-valued attributes
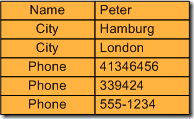
But not only don´t you have to define a schema for a domain and all items/tuples can have a different structure, there´s another deviation from relational thinking: Attributes can have multiple values! So items don´t even comply with the relational first normal form. See the "Phone" attribute in the following item:

It´s not just several phone numbers separated by commas. No! The "Phone" attribute is really structured. You can retrieve (and query for) each phone number separatley. SimpleDB would return the item like this:
Think of what this means: Finally you can set up "natural references" between persistent data like in memory. A parent objekt points to its children. But when you persist these objects in a relational database, you usually invert the references. The child records will contain a foreign key to denote their parent record.
But with SimpleDB you can let parent items point to their child tuples:
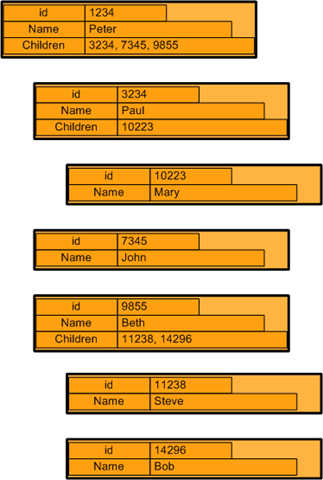
See how all children are referenced with their id values from their parents? See how the number of attributes differ across the items? That´s all just fine with SimpleDB.
Just text
A drawback of SimpleDB might be its limitation to text. All attribute values are stored as just text. So comparison is alphanumeric and leads to effects like this: 20 > 100 because in fact the the comparison is "20" > "100". So be sure to take this into account when storing your non-text values like numbers or dates. Pad numbers with leading zeros (e.g. store "00012" instead of "12"), use a sortable date format (e.g. "2008-01-18"). If you expect to store negative numbers, move them into the positive range of numbers, e.g. instead of "-12" and "12" store "0" and "24" if you expect the value range to start from -12.
On the other hand SimpleDB in this regard does not differ from XML. Text simply is the least common denominator for storing data. Also, this makes SimpleDB more efficient, since it can be optimized for handling text (e.g. in terms of indices).
What´s next?
That´s pretty much all there is to say about SimpleDB´s data model. It´s simple. It´s dynamic.
In my next posting I´ll introduce you to the SimpleDB API. It´s simple, too. Just a couple of easy operations.
But if you want to move forward more quickly, have a look at the SimpleDB documentation on the Amazon website. You can also try out my Open Source implementation of the SimpleDB data model and API. It´s called NSimpleDB and is hosted with Google. More about this too in a future posting.