Screen Scraping in C#
Recently I was asked by a friend of mine to screen scrape a website. What he wanted was the results of a form submission. There were a number of fields on the form (mostly dropdowns), and he wanted me to run every possible permutation of these dropdown lists. All up, this resulted in just over 8,000 pieces of data.
It ended up being REALLY easy (a bit easier than I thought). So I thought I'd share how I went about doing it. Most of these methods were gleaned from other peoples posts, then tailored to my specific needs.
My approach was to tackle this in 2 separate parts:
- Make the requests to the remote server, and save all the possible permutations to disk
- Load up and then scrape the files to extract the data I needed.
Where to Start
I start by firing up Fiddler and make a request to the server just using the browser.
From this I can get the following information:
- The URL I need to send the request to
- All the form fields I need to send with the request
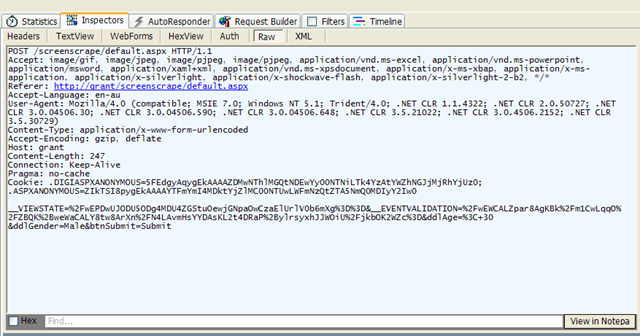
In my case, the server wasn't an ASP.NET server, so I didn't have to worry about VIEWSTATE at all.
Making the request through code
This is one place where I was surprised how EASY it was to make the request. The last time I had to do this was back in the .NET 1.1 days, and it was a little bit harder.
private void SendRequest() { try { WebClient webClient = new WebClient(); // Create a new NameValueCollection instance to hold some custom parameters to be posted to the URL. NameValueCollection vars = new NameValueCollection(); // Add necessary parameter/value pairs to the name/value container. vars.Add("ddlGender", "male"); vars.Add("ddlAge", ">30"); // Upload the NameValueCollection. byte[] responseArray = webClient.UploadValues(URL, "POST", vars); // Save the response. string fileName = "webRequest.html"; System.IO.File.WriteAllBytes(System.IO.Path.Combine(filePath, fileName), responseArray); } catch (Exception ee) { // Log error (omitted for brevity) } }
In my case above, the variables "URL" and "filePath" are set in the constructor of the class.
You will note in the example above that in my case I am using POST to get the data from the server. This can easily be changed to GET (or whatever HTTP method you need).
I save all the response data to a file (which I then parse to get the data I want)
Parsing the HTML files
To parse the files also ended up being extremely easy for me. In the past I've tried to use regular expressions to extract the data from files, but plain and simple... I DO NOT understand regular expressions. I've tried, and where I need to I can get them to work, but my poor little brain doesn't have enough room to remember regular expressions.
This time I used the HTML Agility Pack available through CodePlex. It rocks... Coming from a .NET world, I can understand and use this easily, and its pretty fast as well. For those who haven't heard of the HTML Agility Pack here is an excerpt from their CodePlex homepage.
This is an agile HTML parser that builds a read/write DOM and supports plain XPATH or XSLT (you actually don't HAVE to understand XPATH nor XSLT to use it, don't worry...). It is a .NET code library that allows you to parse "out of the web" HTML files. The parser is very tolerant with "real world" malformed HTML. The object model is very similar to what proposes System.Xml, but for HTML documents (or streams).
private void ParseFile(string fileName) { if (!System.IO.File.Exists(System.IO.Path.Combine(filePath, fileName))) { return; } HtmlDocument doc = new HtmlDocument(); doc.Load(System.IO.Path.Combine(filePath, fileName)); HtmlNode greenBlockContainer = doc.DocumentNode.SelectSingleNode("//div[@class=\"green-block-container\"]"); HtmlNodeCollection greenBlocks = greenBlockContainer.SelectNodes("//div[@class=\"green-block\"]"); string s1 = greenBlocks[0].SelectNodes("//div[@class=\"result-block-left\"]")[0].InnerText; string s2 = greenBlocks[0].SelectNodes("//div[@class=\"result-block-right\"]")[0].InnerText; // etc... // Do something with the data... omitted. }
Here is what the code above does:
- Checks whether the file exists... if not returns
- Creates a HtmlDocument (from the HtmlAgilityPack)
- Load the html file (fileName) into the HtmlDocument
- Extract the nodes we are looking for. Here we can use XPath type queries to get elements
- Use the "InnerText" property to get the value of the node and assign it to a string (I then used this string to populate a DataTable)