Contents tagged with Agile
-
Refactoring to Anti-Patterns
We all know the idea of refactoring to patterns is good. In fact that's generally how I refactor. I see a code smell (say you have a loop that is doing too many things) and refactor to a pattern like Split Loop in order to fix the smell. How about refactoring to Anti-patterns? Or just plain detecting Anti-patterns in unit tests. That's what James Carr is up to here.
Patterns are everywhere and people have been putting togther catalogs of patterns and making them available to everyone (usually through something like a Wiki). Examples can be found here, here, and here. As an off-shoot of pattern catalogs, there are also Anti-Patterns. These are the alternate universe evil version of patterns (yes, just like the evil Spock) and I'm sure you've written them (I know I have). There's a category of Anti-Patterns here and a great site about Anti-Patterns here (including information about Anti-Pattern books).
TDD has patterns, or rather we refactor our code (an exercise in TDD) to patterns. Much like how I described the Split Loop pattern. You see something that smells bad, and think of a way to make it better. Applying a pattern to it is like taking a template idea (one that's been proven time and time again) and adjust it for the situation. Think of patterns as recipes as in baking. They're not rules but rather guidelines as to how to do something. Like baking you might add a dash of this or a hint of that to spice things up. With patterns it's the same thing and you adapt and make small corrections in applying a pattern to your style.
However we can also look at code and see Anti-Patterns. The evil under-doings of things done poorly. Things like the cut and past programming (how many times do you see this?) or the Golden Hammer pattern (where everything is a nail even if it looks like something else and you apply one technology to make it work, can someone say DataSets everywhere?) are examples of development Anti-Patterns.
In TDD there are also Anti-Patterns that crop up. This might be the result of getting to deep into trying to write a piece of code to test and forgetting about what you're really accomplishing. The Mockery or Excessive Setup Anti-Pattern touches on this. Imagine mocking a factory that mocks several calls to each of several factory methods, which returns several mocks, each with several exceptions... Even reading that makes my head spin. And the end goal? Assert.AreEqual(true, businessObject.Value). Craziness!
James has put together a collection of his own (and others) TDD Anti-Patterns. The discussion has been going on in the TDD mailing list for awhile so here's the collection of them. James is looking for some feedback on this so please look at contributing. It might become another catalog resource that we can all use. It'll be great to see this expand as examples are produced complete with refactorings to get yourself out of this TDD Hell.
No, I don't suggest you refactor "to" Anti-Patterns. That was just a title for this blog entry. Rather check out the list and either see if you can contribute to it or maybe use it to find your own code smells in TDD code you've written. You can check out his list here.
-
Simplifing the Scrum prioritization process, part deux
It never ceases to amaze me that as freakingly smart I think I am, how stupid I appear when someone like Ron Jeffries steps into the conversation. He suggested an easier approach to prioritization that Kent Beck and Ward Cunningham taught him:
- Write the ten items, one per card, on ten cards.
- Pick a card and put it on the table.
- Pick another card, and put it to the left of the first card, if it's higher priority, to the right if less.
- Pick another card. Position it to the right or left, or in between the preceding two.
- Repeat until all cards are down.
- Look at the cards pairwise, switching their positions until you're happy.
No muss, no fuss, no wear and tear on your calculator. Works in a group, too.
Brilliant.
Just to note that the matrix approach I posted about doesn’t really scale very well. As you get 50 backlog items you’re now comparing over 2000 individual items so maybe just looking at each item and doing something like the excercise above works better in this case.
-
Using a simplified Analytic Hierarchy Process with Scrum
I was having a discussion tonight with Mrs. Geek and we were chatting about prioritizing and estimating in projects. Yeah, it’s an odd relationship when you talk about this at home but then that’s what makes her Mrs. Geek. Anyways, she’s very scope focused and has done estimating and management on mega-projects but was never exposed to Scrum. I was trying to explain how Scrum works from a prioritization perspective and we got into this conversation.
As we got into it I explained how Scrum generally worked with prioritizing features. Not a lot of info is out there on *how* to prioritize, just that it’s part of the process. The Product Owner (PO) is meant to prioritize this list, however a lot of times while they may know what’s important to them, if it’s one person doing the prioritization you might miss some different perspectives.
Most people practicing Scrum say the PO does know his thing and will do the prioritization correctly, however a lot of times when new teams are adopting Scrum they may not have an approach other than something very traditional. For example Dmitri Zimine has a blog entry here on how to prioritize the work, but his technique is like most might think. Put the list up on a wall and assign values to each item (1–9, a-z, whatever). This is fine and produces a list but it’s hard to say if this is prioritzed very well or not.
Also there are many examples out there that show Product Backlog items like “Setup development environment” or “Provide Extract from Database to External Sources”. How is a Product Owner who has little or no knowledge of say the IT infrastructure or their processes supposed to prioritize this? To an IT guy, this is most important (and required to say do other things like oh, test the application) but for others that are more business oriented they might see this as low priority.
So let’s start with the traditional approach. Put together a list of items (our Product Backlog) and having the Product Owner prioritize it. Here’s our prioritized list:
Priority Backlog Item 1 Setup Development Environment 2 Ability to sign up for memberships 3 Ability to use credit cards to pay for memberships 4 Notify members with membership data 5 Generate receipts and certificates 6 Authoring environment for articles 7 Web site look and feel and initial navigation 8 Display sponsors and links to web sites 9 Organize and sort articles 10 Library catalog for articles Our PO thinks that the ability to organize and sort articles isn’t that important and more importantly is the ability to notify members with membership data (perhaps to publish a newsletter). We’re not sure based on these items what some of this means, or the method they went through to arrive at this order but we have to go with it as that’s what the customer wants right? I find the process to create this list to be flawed. While it’s great that the PO has put together the priorities, he does so by only looking one dimensionally at the values. Also whether they knew it or not, they’re probably not really looking at the entire list each time they try to prioritize each item.
For example, once you’ve gone through the first 5 items in our list you have their weights setup and assigned. Subconsciously I think you now dismiss those items for future planning. Sure, you’ve weighed those items against others (like Membership to Authoring) but when it comes to prioritizing Authoring, you ignore the inverse comparison of Authoring to Membership as you’ve already prioritized Membership. That’s cheating the process a bit and not giving the Authoring feature a fair chance. It only has to compare to what the left over items are and we know that inverse comparisons are not always just as simple as the opposite of what you’ve already looked at.
Enter a technique called the Analytic Hierarchy Process (AHP). This is an organization approach that focuses on the relative importance of objects to each other. This will take us from looking at our Backlog in one dimension to looking at it in two, and the outcome is a more well defined set of numbers that tells us what the priorities really are. In a nutshell, it does so by comparing each item to another item, then adding up the values for each item to arrive at a weight (or ranking, priority, whatever you want to call it).
Now, as Scrum is a simple process unto itself I wasn’t too happy when I read through the various explanations on AHP. Edwardo Miranda has a great white paper called “Improving Subjective Estimates Using Paired Comparisons” on how the process works. However once I saw those crazy mathematic symbols explaining the calculations behind it, my blurry college and university years came rushing back and I almost blacked out. James McCaffrey has a short MSDN article on using the process which didn’t get into as deep as Edwardo’s explanation, but I still thought it was too complex for Scrum.
Like I said, this whole conversation started tonight as we were talking about project estimates and priorities. Then it hit me that you could take the uber-simple process of tossing items into a list but apply AHP to it to get something a step above, but not as freaky as learning thermo dynamics or theoretical physics again. We went through this process while discussing the subject tonight so let’s take a look at how we can come up with a better list of priorities than what we have above.
Break out Excel (or do it on a white board for that matter) and set up your items as rows and columns in a matrix. Something like this (I’m using numbers for each item in the top row so it’s easier to read here, but you might want to use the full names set at an angle in your spreadsheet):
Feature Name 1 2 3 4 5 6 7 8 9 10 1 Setup Development Environment 0 2 Ability to sign up for memberships 0 3 Ability to use credit cards to pay for memberships 0 4 Notify members with membership data 0 5 Generate receipts and certificates 0 6 Authoring environment for articles 0 7 Web site look and feel and initial navigation 0 8 Display sponsors and links to web sites 0 9 Organize and sort articles 0 10 Library catalog for articles 0 The order isn’t important here so it can just be your raw Product Backlog. Now go to each cell and compare the Feature to the other Feature in each column along the row (comparing the same item is redundant so it’s ignored and indicated here with 0). For example we’ll start with Setup Development Environment (Item #1). Is it more important, less important, or just as important as the ability to sign up for memberships (Item #2).
Give it 1 if it’s less important, 5 if it’s the same, and 10 if it’s more important. I find the 1–5–10 combo to be easy to use and remember. It’s either obvious it’s the same or more/less important. While you can assign say a number from 1–10, it starts creating long winded discussions like “Should it be a 6 or a 7?”. That’s detrimental to the exercise and you really don’t want to go down that rat hole.
A couple of things to note as you go through the items. You can compare Features from any angle you want. Sometimes it might be the business value, other times it might be risk or cost or whatever. You have to decide what’s best for the overall product. Also make it simple but don’t spend more than a couple of minutes for each item. Don’t try to keep track in your head of what the last compare was as it might taint what you’re really trying to compare against. Just focus on each item to each item then move on. Plain and simple.
Once you’ve done the first comparison, do the next column over and keep going to the end. Then start the next row and repeat the process. You’ll end up with a grid that looks like this:
Feature Name 1 2 3 4 5 6 7 8 9 10 1 Setup Development Environment 0 1 1 1 1 10 10 10 10 10 2 Ability to sign up for memberships 10 0 5 10 5 10 10 10 10 10 3 Ability to use credit cards to pay for memberships 10 5 0 10 5 10 10 10 10 10 4 Notify members with membership data 10 5 1 0 5 1 1 1 1 1 5 Generate receipts and certificates 10 10 5 10 0 5 10 10 10 10 6 Authoring environment for articles 5 10 10 10 10 0 10 10 5 5 7 Web site look and feel and initial navigation 10 1 1 1 1 1 0 5 1 1 8 Display sponsors and links to web sites 10 5 5 10 5 5 10 0 5 5 9 Organize and sort articles 10 5 5 5 10 1 10 10 0 5 10 Library catalog for articles 10 5 10 10 10 5 10 10 10 0 Looks good and yes, it does take some time. For 10 items, you’re doing 90 comparisons but don’t cheat. Do the actual comparison. Think about if it’s really more or less important (or the same) and be honest. Just like you do an estimate on a task, think about it from whatever angle that makes sense. It does give you perspective on things and lets you look at your list in a different light. The heart of the application, the core functionality that’s most important will bubble up eventually. For example in our scenario here, the PO felt that item #2 (sign up for memberships) was more important than item #4 (notifying members with membership data) but about the same as using credit cards for membership. Maybe that was a revenue decision, maybe it was functionality. Doesn’t matter as long as there was some thought behind it. Also try not to look at the other values. You won’t be doing yourself any service if you just replicate the inverse of the other values as that’s no different than doing a one-dimensional list. If you’re capturing it in Excel, just hide the first row when you move onto the next.
Now that you’re done, add up the values across the columns. This is our weight for each Feature. Now sort the list based on the value for that total and you’ll have your prioritized list. It’s that simple. Here’s our result from this exercise:
OR Feature 1 2 3 4 5 6 7 8 9 10 R 2 Ability to sign up for memberships 10 0 5 10 5 10 10 10 10 10 80 3 Ability to use credit cards to pay for memberships 10 5 0 10 5 10 10 10 10 10 80 5 Generate receipts and certificates 10 10 5 10 0 5 10 10 10 10 80 10 Library catalog for articles 10 5 10 10 10 5 10 10 10 0 80 6 Authoring environment for articles 5 10 10 10 10 0 10 10 5 5 75 9 Organize and sort articles 10 5 5 5 10 1 10 10 0 5 61 8 Display sponsors and links to web sites 10 5 5 10 5 5 10 0 5 5 60 1 Setup Development Environment 0 1 1 1 1 10 10 10 10 10 54 4 Notify members with membership data 10 5 1 0 5 1 1 1 1 1 26 7 Web site look and feel and initial navigation 10 1 1 1 1 1 0 5 1 1 22 The “OR” column is our original ranking we did just by looking at all the items and coming up with the priorities. The “R” column is the weights calculated by adding up all the item to item compares.
Notice that after going through this, we find out that the all-important Setup Development Environment Feature is way down on the priority list, the Library Catalog for Articles that was the least important item now is somewhere in the middle, and the look and feel (when all is said and done) really is the least important item and should be done last. These are valid numbers as the PO went through and decided, on an item by item basis, what was important at the time.
Now this isn’t to say that this is gold. For example, we may need to setup the development environment in order to deliver the ability to sign up for memberships. This is where I belie the entire team, not just the PO, should prioritize the items (unless the PO really knows everything, which is rare). The PO should be telling the team why something is important while the team works out what’s risky or perhaps required for some items to be delivered.
A little negotiation goes a long way, but the main thing is that you get to see what’s really important here and why. Along with the why, you get to see the what. There are a lot of things that are 80 here but when you compare one item to the next, there are subtle differences. This will help when you have all those #1 items to deliver in Sprint 1 and don’t know which one to start on first.
Okay, this is a mythical example using made up values and such, but it really does work. It provides you a better weighting of what’s important and does put some pseudo-science behind it. As I said, AHP in it’s traditional form can be complex and what I’ve presented here is a simple version of it. In trying to keep with the tradition of Scrum being simple, I hope this echos that. You can, as you see fit, add layers to this process (or choose not to adopt it at all). For example, you can take those weights and apply them to estimates (costs) in your system to figure out what the best bang for the buck is (thanks to Mike Cohn for that tip).
Use what works for you but when you’re done the idea is that you might end up with a more accurate view of the prioritized world before you begin your Sprint.
P.S. Completely unrelated (but I found it while I was checking some references for this article) I noticed Mountain Goat Software, the site Mike Cohn runs got a major face lift. Looks a lot nicer now and easier to navigate. Check it out here as there’s lots of great articles and resources there on Scrum.
-
Scrum Tools Roundup
Working this weekend on some new SharePoint stuff which you’ll see in a few weeks but thought I would pull together a list of tools to help people with Scrum. These are tools that help you plan iterations, keep track of your updates, and generally make life easier for the ScrumMaster or those working on Scrum projects. Not to say a plain old whiteboard with post-it notes or Microsoft Excel won’t do the trick, but these tools take you a little bit farther and help you keep track of things holistically.
Some are open source, others are not so check them out if you’re looking for something extra to add to your Scrum process. Where noted, I’ve given some suggestions about using these tools where I’ve already taken a look at them for you, but please make up your own mind with your own eval if you’re serious about a product (especially one that costs $$$).
Scarab
Java server based artifact tracking system, highly customizable. Distributed under a BSD/Apache style license.Double Chocco Latte
Sounds more like a special at Starbucks but this is a package that provides basic project management capabilties, time tracking on tasks, call tracking, online document storage, statistical reports, and a lot more. PHP based, supports both Apache and IIS, MySQL or SQL Server (and others), web based client. Distributed under the GNU General Public License (GPL).VersionOne
This is a commercial product that provides program, project, and iteration management and fully embraces the Scrum process through requirements planning, release planning, and iteration planning and tracking. Trial version can be downloaded and run locally. Runs under ASP.NET and IIS with a SQL backend. I’ve given VersionOne a test-drive in the past and it’s complete and a good, solid product. The only thing is that it’s got a LOT of options so if you’re looking for something simple, this isn’t the tool.GNATS
GNATS is traditionally a bug tracking tool, but according to Jeff Sutherland it’s Scrum-ready (whatever that means). Licensed under the GNU General Public License (GPL).Select Scope Manager
A commercial web-based package that provides planning capabilties to all aspects of Scrum and XP projects. Evaluation version available to download from site. I’ve worked with some Select products in the past and they’re not bad, but not very customizable.XP Plan-it
This is a hosted solution so you only need download the client and retrieve data from their servers. Commercial package but doesn’t seem to be anywhere you can download anything or even see the product. I would stay away from this one.Iterate
This is an interesting tool and very simple in appearance. It basically provides an electronic version of story cards and does some tracking (like your velocity). It’s simple but maybe too simple and personally I felt the interface seemed like an old VB app that someone threw together. Still, I think it works.TWiki XP Tracker Plugin
Here’s a bit of a switch and not a stand-alone tool but a plugin for a wiki system (TWiki). It provides custom templates and helps you track information on XP projects. While not really Scrum related, it does let you track stories and releases so you might have to modify it in order to fully use it for Scrum (Scrum != XP). TWiki is released under the GPL and is Perl based (blech) so as long as you can run Perl you can run TWiki.XPCGI
This is an open source Perl based system built for Linux and Solaris running Apache 1.3 or higher. They claim it will work on other platforms, but YMMV.XPWeb
Another web based project that’s distributed under the GNU General Public License (GPL). Uses PHP and MySQL so running under Linux, Windows, or Mac should be fine. The demo doesn’t render under IE7 so I couldn’t check it out for you.XPlanner
Probably the grand-daddy of the open source projects of this type, XPlanner is distributed under the GNU Library or Lesser General Public License (LGPL) and free. Requires Apace Tomcat to run so expect to spend a little time setting this up on Windows (but it does run as I’ve done it). Lots of options, pretty stable, respects Scrum and XP and how they work, and very simple to use. Actively being worked on and many open source projects use it for their own planning (Hibernate, JUnit, Log4J, Struts, etc.) so updates are pretty frequent.ScrumWorks
A professional looking product that touts features to support all aspects of Scrum. Support single or multiple teams working on the same or different projects. Client based but has a Web Client as well for some members of the team (say your PO that doesn’t need to get down and dirty with Sprint Backlog Items). Requires a trial license but you can get a copy for free just by requesting it. Nice piece of software that is backed by support forums, a wiki, and an API for extending it’s capabilities.ProjectCards
An interesting project that offers the ability to cover all aspects of Scrum (and then some). Very customizable down to custom fields you can display and use in reports. Client/Server based but features a plug-in for Eclipse if you have it in your environment. Guest accounts are unlimited and free (so POs and non-core team members can just use it to view the status of a Sprint). Downloadable trial but the full version will set you back some Scrum bucks.TargetProcess
I really like this tool, but maybe because it’s .NET web-based. It’s simple to use and setup and cost-effective for teams. While it doesn’t feature as many screens as other products, what it does supports Scrum and Agile projects with simple inputs and direct reports and charts. Nothing fancy but then neither is Scrum. Free trial avaiable and demo available online and you can download a 1–user pack completely fully featured and free (but with no support) so it’s great if you’re doing little one-man projects and you just want something to keep track of your progress and work. Supports SQL Server and MySQL but requires IIS and ASP.NET so it’s Windows only.ExtremePlanner
Lots of features for this commercial package, but not a lot of customization available so you can’t completely tailor it to your process. Requires Windows, Linux, or MacOSX platforms to run on (with Java 1.4.2 or higher and Apache Tomcat 4.1 or higher) or you can let them host your projects for you (for a fee of course). Simple interface makes it easy to enter information and covers all the aspects of Scrum planning including test case tracking and typical burndown charts.Rally
Enteprise level hosted project solution. Tons of features and lots of customization available (even for an online hosted system). Met these guys in Calgary during Agile World a couple of years ago and back then the product was impressive, so I can only imagine what they’ve improved on. Free demo online to check out and setup a project to see if it works for you.Scrum for Team System
Saving my personal fav til last. We’re using this on a few projects now and it rocks. An add-in guidance package for Microsoft Team System, it fully covers Scrum and lets you get work done fast. No customizable available but it works without it. Co-developed with Ken Schwaber so it reflects how Scrum needs to be done. Let’s users create their own views but comes with a dozen or so that are quite sufficient. Supports single team or multiple team projects and is currently being updated to version 2.0 where it’ll have more flexibility. If you have Team System in place and are struggling with the MSF for Agile package then take a look at this, you won’t be disappointed.Bottom Line
If you’re a one-man shop, I suggest you check out TargetProcess as it can be setup in a few minutes on a server or your own development desktop. If you already have Team System in-place, take a look at Scrum for Team System. If you have nothing but could run say Tomcat, then XPlanner might be the way to go as it’s simple but works well. Give a couple a test drive and see what’s best for you. -
Getting started with Scrum
Mike Cohn over at Mountain Goat Software has been in the Agile software development river since 1993. He's the author of the most excellent book Agile Estimating and Planning and really knows his stuff.
For those wanting to greenfield Scrum at your organization, he's got an excellent powerpoint slide deck to start from. It talks about what Scrum is and highlights the key things that you can use to show benefit to management. Mike encourages people to download the presentation and run with it, making adjustments as you need to adapt it your environment. The killer thing about this is the presentation is available under the Creative Commons Attribution 2.5 License. This is excellent for the Scrum community as we can go off a base from a respected source. I encourage everyone to join the bandwagon and help promote this by making it work for you. Scrum isn't a silver bullet, but it just plain works. You can grab the slide deck from here. Also available is a French version generously translated by Claude Aubry.

To add some icing on the cake, there's some great pictures of the Scrum process that Mike has made available of the process itself which really sums it up. These are great for decks or just print them out as a poster to hang in your team area to let everyone know the simplicity of the process. You can check out the picture files, also released under the CC license, here.
Watch for the Scrum tatoos coming soon to a blog near you.
-
First iteration done as in dinner
Well, 30 days later and our first sprint is done. We finished ahead of schedule at about 2pm the day before the sprint “officially” ended with one task remaining that the QA guy had to do. It was a fun ride and challenging. The entire team (sans me) had to deal with the following new technologies:
- Smart Client Software Factory
- Composite Application UI Block
- Enterprise Libraries
- Model-View-Presenter
- .NET 2.0 and Generics, Delegates, etc.
- ClickOnce
- Unit Tests
- TDD
- Visual Studio 2005
- Team System
As well as adapt to the Scrum process as they were mostly used to waterfall-esqe approaches (BDUF, highly detailed specs, etc.). I think everyone adapted pretty well. We had some churn the first couple of weeks as the plumbing got settled, we got used to using Team System (as a team) without clobbering each others work. Here’s the burndown from the iteration:
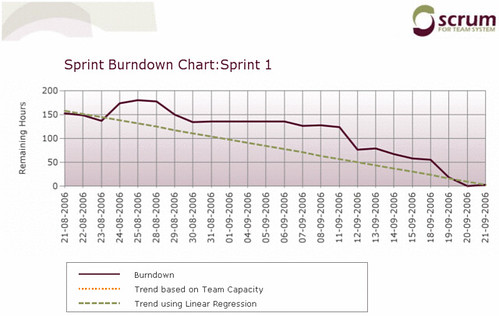
Things were a little goofy. First off I entered all the features into the Product Backlog, but then another guy (while I was enjoying the backwoods of B.C.) entered the same set and deleted my initial ones. Then we forgot to enter the initial estimates for the sprint. Finally we had entered the estimates but then had entered them in hours and Scrum for Team System uses days for the product backlog items. So that explains the false start (I’m still trying to manipulate the original warehouse database to correct that).
The other three gaps were caused by over estimation. On the 28th of August, we introduced a data layer using NetTiers and a few simple tables. That knocked two tasks that were pegged at 14 hours each down to nothing in a day. On the 11th of September we did the same thing for the next set of data we needed to store. Finally on the 18th of September we realized there were 3 or 4 tasks that were estimated at about 8–10 hours but they were really just rolled up in another screen, so that was knocked off in a day.
Not the prettiest sprint burndown chart out there, but it’s real numbers.
As for our Sprint Review, that was almost a huge guffaw. Our review with the customers was yesterday at 10am. We had stopped development and put out a release for final QA testing by noon the day before. Everything worked fine. The QA guy and some devs were working until about 9pm that night either just admiring what we did or were adding little things we wanted to put into the system (but we weren’t going to show this) and all was well. Then at 7:30 the next morning, our QA came in and couldn’t run the app. By the time 9am rolled around and we were checking the release to go over the demo, nothing worked. We tried on every machine and still no dice.
At 9:30 we reset the database and I thought we had done something horrible because the app wouldn’t even launch. Man, we were sweating bullets. Finally we determined that something happened with the proxy server on the network, so launching our ClickOnce app was failing and the exception handler couldn’t deal with it (for whatever reason). The network guys push stuff out all the time but apps for this customer never were this complicated, so nothing ever was affected. Anyways, to get the demo up and running we commented out some handling and it ran fine.
As we were really cramped for time and didn’t have time to start up the laptop to demo the system, I didn’t want to chance having that fail so we grabbed the one dev’s desktop (a Dell Dimension E521), his keyboard and mouse and screen (luckily it was a LCD and not a CRT) and hauled ass across the street to the building where we did the review.
At the end of the day, the customer was happy with what we did. There were a few suggestions and ideas that we’ll add to the next sprint. We spent an hour and a half going over the backlog items for the next sprint and ended up with a nice list to deliver the first release at the end of October. That burndown will be more of a slope than a bumpy ride, but the team had fun and we delivered working software which was the key thing.
One more note. We couldn’t figure out why when we were going through the product that a list of values were not coming back from a corporate web service. A different list we used was being populated from that same service, but the one list of numbers we wanted wasn’t. Later that day I found out that one of the devs in the other building had deleted that web service method because he thought it was a duplicate. Luckily, our system was built using Smart Web References (part of the Smart Client Software Factory) and will simply return us the list of values and a success/failure value of the web service call. This isn’t exposed to the user, but at least the app didn’t hit and unhandled exception during the demo. Thanks Les!
-
Joel on Team System
Just listening to Joel Semeniuk on the latest podcast of .NET Rocks! as they talk about Team System. As a Scrum-junkie, I really love the fact that Microsoft did something right with Team System when they left the system open. It opened the door for people like Conchango to put out their very excellent Scrum for Team System set of process templates. As Joel mentions in the podcast, for a developer who’s savvy with Team System but doensn’t know about Scrum the plugin lets you understand Scrum a little better, and vice-versa for the Scrum guy who doesn’t know Team System. It works for both types of developers which is nice. If you’re trying to struggle with Team System, or you’re trying to get Scrum working with the MSF Agile template MS ships then you might want to take a look at Scrum for Team System. It’s very slick (and free!).
-
Ken Schwaber introduction to Scrum video on Google Tech Talks
Ken Schwaber is the co-founder of the Agile process called Scrum (which BTW is not an acronym) recently gave a talk which has been put online via a serivce called Google Tech Talk.
It’s an hour long presentation but gives you an excellent introduction to Scrum (if you’re not already familar with it) including the interesting history behind it. If you don’t know what Scrum is and are interested (or haven’t heard Ken talk as he’s a great speaker IMHO), you can check it out here.
Nothing like getting the facts straight from the horses mouth (so to speak).
-
Exposing business objects to the UI
I've been working the past few months with the Composite UI Application Block (CAB) and the Smart Client Software Factory (SCSF). They're all great but the documentation throws me for a loop sometimes.
In an entry called "Map Business Entities into User Interface Elements" it suggests creating a mapper class and using it to convert some business object into a UI one. This makes sense however the implementation and references cause my head to hurt.
In a typical MVP pattern, you have the Model (your business object), the View (the UI), and the Presenter (a go-between guy). The presenter knows about both the view and the model. It needs to inform the model to update based on messages recieved from the view, and tell the view about changes in the model. Neither the model or the view have any knowledge of each other.
Introduce the mapper which knows about the Model and the View. This is the other side of the equation so when given a business object, the mapper will spit out a drop down list, a grid control, or whatever UI element is appropriate to display something from the business layer (say a list of customers).
In the example Microsoft provides via the guidance package, the view has a method that accepts a business object which then calls the mapper to translate it into a ListViewItem. The view then updates its UI control (a ListView control) by adding list items to it created by the mapper.
However this means that you're exposing you business objects to the user interface, which creates a coupling between the UI and the business layer (at least from a deployment perspective). If you don't do it this way you have to have the presenter (which should know about domain objects so that's ok) update the view but what is it going to update it with? Certainly not a ListViewItem which will make the presenter dependent on the windows form control assemblies.
Without creating a intermediate object (like a CustomerDTO with nothing but getters/setters) are we really bound to have the UI reference the business layer and is the documentation here really a best practice for exposing business objects to the UI? How do you guys do it?
-
TDD validation... NetTiers Style
Let’s face it. At the end of the day, even the most purist of us object-oriented bigots know the real truth. Objects need data to work. Yes, behaviour defines an object and all that OOD popycock but I mean, a Customer domain object still needs a name, telephone number, and address in order to be of any value in an Enterprise system right? Sure there are “business rules” we want to write but all the unit tests in the world are not going to get around the fact that objects need data and sometimes that data needs to be saved (or retrieved, or both).
The problem we all face, sooner or later, is how do I get data from some datasource (for the sake of the argument here, let’s say a database) into (and out of) my object? There are really two ways to go about it and for the purpose of this article, let’s avoid the O/R mapping ramble. So that leaves us plucking data from properties exposed in a business object and shuffling it off to parts unknown to be stored somewhere. Service objects and Repositories and Mappers and Translators and all kinds of other things having intimate knowledge of the types and properties of domain objects. On the flipside of this, there’s a pattern called ActiveRecord that follows the principle that an object would communicate with an outside service and publish it’s properties for persistence (or the other way round loading data from a data source). Neither of these situations is really pleasant but it’s a bear we deal with when we have to shut down machines and expect that information to be there tommorow.
The latest version of a set of CodeSmith templates called NetTiers provides us with an interesting way to look at our domain (and getting it to/from a database). CodeSmith is a code generation tool and using the NetTiers templates, it creates a n-tier set of classes (about 90 of them from a simple database) that allow you to do cool stuff like this:
DataRepository.MyObjectProvider.Save(MyObject);
This is all neatly wrapped up in a transaction (if the database supports it and/or you configure it to use transactions) and all dynamically generated based on tables and columns in a database. It’s all very slick and NetTiers can create an entire app (minus the front-end) for you in less than 10 seconds. So what’s this got to do with TDD?
Imagine we’re starting an application and we’re going to be building it using TDD. We have some requirements and we’re ready to start writing tests. Given a requirement that a Customer name can not exceed 50 characters we might write a test like this:
namespace NetTiersTDD.UnitTests
{
[TestFixture]
public class CustomerFixture
{
[Test]
[ExpectedException(typeof(ApplicationException))]
public void CustomerNameShouldNotExceed50Characters()
{
Customer customer = new Customer();
customer.Name = "X".PadLeft(51);
}
}
}
This is fine and a good start. So now we create our business entity to support the test:
namespace NetTiersTDD.Entities
{
public class Customer
{
private string _name;
public string Name
{
set { _name = value; }
}
}
}
Great. Our unit test compiles but out test fails (which is good, remember Red-Green-Refactor). Now let’s make the test pass in our business entity:
namespace NetTiersTDD.Entities
{
public class Customer
{
private string _name;
public string Name
{
set
{
if(value.Length > 50)
throw new ApplicationException();
_name = value;
}
}
}
}
Fantastic. So this can be typical when doing something like these checks. There are other checks you might do and the general idea is around failing fast so you would throw an exception when some validation fails on your business entity (you don’t want to find out your domain object is invalid several layers or operations down the stack).
Fast forward about 3 days and you find yourself slugging through requirements like this (and others) and your classes start buffing up and out. More domain logic, lots of tests, goodness. However, you might notice something happening with some of your tests. Take a look at our Customer test now:
namespace NetTiersTDD.UnitTests
{
[TestFixture]
public class CustomerFixture
{
[Test]
[ExpectedException(typeof(ApplicationException))]
public void CustomerNameShouldNotExceed50Characters()
{
Customer customer = new Customer();
customer.Name = "X".PadLeft(51);
}
[Test]
[ExpectedException(typeof(ApplicationException))]
public void CustomerAddressShouldNotExceed255Characters()
{
Customer customer = new Customer();
customer.Address = "X".PadLeft(256);
}
[Test]
[ExpectedException(typeof(ApplicationException))]
public void CustomerAgeShouldNotExceed65()
{
Customer customer = new Customer();
customer.Age = 66;
}
}
}
(note: I’m using ApplicationException here but you would probably have a specific exception for different validations)
Lots of exceptions being thrown because well, it’s a business rule violation. By design, we don’t want to make our domain object invalid by any means so we throw an exception when setting a property that’s invalid. This will immediately let us know something is wrong and, if we had a UI, we could inform the user of the error (maybe with a Message Box telling him that a field is too long or required or whatever). This is fine and dandy but makes me queasy. I mean, exceptions are expensive. Imagine I had an import routine that brought in crappy (un-validated) data from an Excel spreadsheet and created 1,000 domain objects in a collection. That’s a heck of a lot of exceptions.
An alternative is to post-validate an object. That’s a valid approach. Let whatever information come into the system (from a user or that crappy spreadsheet) and validate the object after the fact. Then I can do something like check an IsValid property (or the return value from a method called Validate()) and act accordingly. I’m still not letting my domain object get out of control because the unit of work hasn’t completed until I validate the object so we’re good to go. This is okay but now we need a Validate method, some way to retrieve the validity of our business object, some way to set the rules for various properties, and other “helper” methods. Some astute readers will jump up and say “I know, let’s decorate properties with attributes and use reflection in a standard method to validate a setter”. Cool and nice out-of-the-box thinking and certainly something you could do (and something that might start to drift into AOP territory but that’s a whole ‘nuther can o’ worms that I won’t get into either).
So other than reflection, I now have to write a bevy of code to handle validation, invalid state, modify changes to properties (or maybe respond to them) and lots of other little niggly bits. If I was being paid by the line then maybe I want to do this. And hey, if I build a framework we can use it everywhere in the organization so it’s an investment. Yes, this is again a valid thing to do but my motto is don’t write something that can be created by a tool for you (and works). Using the validation framework generated from NetTiers, we can get all this (and more) for a pretty insignificant cost. On top of that, we have a DAL written for us that we don’t have to worry about and can use later when we need to persist our business entities (and what application doesn’t do that?).
Again Bil, what the heck does this have to do with TDD?
Like I said, NetTiers (via CodeSmith) will generate billions of lines of code for you with the single click of a button. Buried in that code are some base classes that NetTiers will use with your business entities (gen’d from your tables based on it’s columns and constraints) and buried deeper down than that are some pretty cool utilities and classes that you can use to write less code (but get more accomplished). I’m all for something that works and let’s me write less code to get more done and that’s what I can get from NetTiers.
Let’s go back to our Customer class and try some NetTeirsTDD. First thing is you need NetTiers to generate you it’s artifacts. This involves creating a database and a table. Yeah, I know. TDD. Database. The TDD guys are saying “Oh man, he’s got it all wrong”. Just walk with me on this okay?
Create a new database and add a simple table to it. Here’s the one I used:
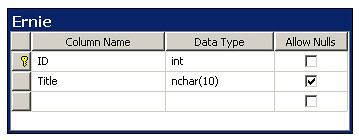
The table is called Ernie with ID and Title columns. The name and columns really don’t matter so you can call it Temp, Balloon, Mayonaise, or Wurstie for what it’s worth. Just call it something that won’t be one of your business objects because hey, we’re doing TDD and we don’t create business objects until we need them right? The temp table (and resulting generated code) is so you have a starting point (and a framework to leverage, which is what we’re getting to).
Now run CodeSmith using the NetTiers templates. In the latest version (2.0) of the template, you’ll need to set a few things:
- Point it at your datasource via the ChooseSourceDatabase property
- Set IncludeUnitTest to True (this will create a unit test project)
- Set LaunchVisualStudio to True
- Set GenerateWebLibrary and GenerateWebSite to False
- Set ViewReport to False (or leave it on if you want, your choice)
Once those options are set hit Generate. In about 10 seconds you’ll have about 60 classes, 4 projects, and the basis for your starter solution.
Finally let’s get into some TDD. Go to the opened instance of Visual Studio with the solution that was created for you. The unit test project that you created will already have references to the various other projects (including a raft of unit tests to test persistence of your Ernie class). Let’s go back and start our Customer test again, except we’ll do things a little differently.
First let’s modify the test that we originally wrote. Instead of expecting an exception, we’ll use an IsValid boolean property:
namespace NetTiersTDD.UnitTests
{
[TestFixture]
public class CustomerFixture
{
[Test]
public void CustomerNameShouldNotExceed50Characters()
{
Customer customer = new Customer();
customer.Name = "X".PadLeft(51);
Assert.AreEqual(false, customer.IsValid);
}
}
}
Looks harmless and something we might do. IsValid will return true or false if the customer object is valid (and in this test, we want IsValid to return false because we expect it to be that way after setting the name with too many characters). Now here’s where the magic comes in. Create your Customer class but inherit from a class called EntityBase (a class that’s part of the framework NetTiers created). To get this code setup to compile, EntityBase requires a few abstract methods to be implemented. They don’t have to do anything (for now) so you have a couple of options (like create a StubEntityBase and implement the methods in that). So let’s do that make our Customer class work. Create a class called StubEntityBase with these members implemented like so:
public class StubEntityBase : EntityBase
{
public override void CancelChanges()
{
throw new Exception("The method or operation is not implemented.");
}
public override string TableName
{
get { throw new Exception("The method or operation is not implemented."); }
}
public override int ID
{
get
{
throw new Exception("The method or operation is not implemented.");
}
set
{
throw new Exception("The method or operation is not implemented.");
}
}
public override string Title
{
get
{
throw new Exception("The method or operation is not implemented.");
}
set
{
throw new Exception("The method or operation is not implemented.");
}
}
public override string EntityTrackingKey
{
get
{
throw new Exception("The method or operation is not implemented.");
}
set
{
throw new Exception("The method or operation is not implemented.");
}
}
public override object ParentCollection
{
get
{
throw new Exception("The method or operation is not implemented.");
}
set
{
throw new Exception("The method or operation is not implemented.");
}
}
public override string[] TableColumns
{
get { throw new Exception("The method or operation is not implemented."); }
}
}
Now inherit Customer from StubEntityBase instead of EntityBase.
public class Customer : StubEntityBase
{
private string _name;
public string Name
{
set
{
_name = value;
}
get
{
return _name;
}
}
}
Great, run the unit test and it fails. IsValid returns true because we haven’t put any validation checking in our business object yet. Now it’s time to make it pass. Change the Customer class to show this:
public class Customer : StubEntityBase
{
protected override void AddValidationRules()
{
ValidationRules.AddRule(
Validation.CommonRules.StringMaxLength,
new Validation.CommonRules.MaxLengthRuleArgs("Name", 50));
}
private string _name;
public string Name
{
set
{
_name = value;
OnPropertyChanged("Name");
}
get
{
return _name;
}
}
}
We’re doing two things in the business class to make our test pass. First, we’re overriding a method called AddValidationRules. This gets called (lazy loaded) when a validation check is done (for example when you call IsValid). The ValidationRules is a list of rule objects (again, classes in the NetTiers framework) that you can setup. The CommonRules contains things like length checks, required fields, not greater than, etc. You can also get into designing your own rules but that’s for another blog. So we tell it to check the property named “Name” and make sure it doesn’t exceed 50 characters. If it does, it adds a BrokenRule object to another list.
Then we add a call to the setter for name to trigger an event called “OnPropertyChanged” and pass the name of the property we’re setting. This will do a validation check against the property by invoking any rules that match the property name (you can have multiple rules per property).
Finally when the IsValid property is called on the business entity, it checks the ValidationRules list, finds a list of BrokenRules (rules that failed validation when the OnPropertyChanged event was called) and returns true of the count is not 0.
Cool huh? Lots of business validation stuff going on but none of the plumbing we had to write to get it. There are some other neat side effects that you can get from this framework. For example, back in our unit test we can just ask the object what the error(s) are and print them out:
[Test]
public void CustomerNameShouldNotExceed50Characters()
{
Customer customer = new Customer();
customer.Name = "X".PadLeft(51);
if (!customer.IsValid)
Console.WriteLine(customer.Error);
Assert.AreEqual(false, customer.IsValid);
}
This prints out:
------ Test started: Assembly: NetTiersTDD.UnitTests.dll ------
Name can not exceed 50 characters
1 passed, 0 failed, 0 skipped, took 0.56 seconds.
Very useful when writing out the errors to the screen or a log (rather than having to figure out what the error was, then compose a message for it).
Let’s go back to what was originally generated with that first cut off the database. By default, NetTiers generates a report showing you all the craziness it did. This includes a plethora of classes like ListBase, EntityFactory, BrokenRule, ValidationRules, EntityCache, EntityPropertyComparer, and a bunch of other classes. These classes actually have nothing to do with data persistance but form an object framework that we can use (like above) to validate our business objects.
These are all generated by the tool but are used by business entities. For example, ListBase is a generic list (just like List<T>) but supports searching, filtering, sorting, and databinding. Feel free to load up business entities into it and bind it to a GridView for some fun. EntityCache is a class that you can use to add entities to a cache manager. The manager is actually driven by Enterprise Libraries (which the NetTiers code is built on top of) but it lets you add your own business entities to a cache and find them later. This can be handy for in-memory Repositories or just quick and dirty tests where you need to retrieve known objects (but don’t want to create singletons or something). There’s lots of great classes and helpers that are generated for you and all it takes is a single table to get going (which you can delete later and all the code for it will wash away) so explore the business entity project that gets created and check it out (there’s also full documentation on all the classes and methods that you can create using something like Sandcastle).
Finally, at some point you will (or probably) have to save your business entities data in a database. Again, this is where it gets simple (but it’s a bit of a manual process). Let’s say you’ve written up your object with various rules (not just length checking stuff but real business tests) and need to save it. You take a look at what the business object has and decide on a structure. Just a simple structure since all you really need to do is CRUD. Create the table and regen the DAL using CodeSmith and NetTiers (saving your business validations before you do this). Now just drop the business validations in the new genrated object that will derive from MyObjectBase and you’re good to go.
Let me clarify the steps I described above:
- Write your unit tests and create whatever business classes that come out of your tests (adding your business classes to the Entities project NetTiers generated)
- Identify what properties you need to persist from your business class and create a simple table with the same name as the class to hold them
- Rename your business class to a placeholder (like MyBusinessObject.txt)
- Generate the DAL from the database
- The Entities project will contain one business class for each table created. This class is split into two parts. MyBusinessObject and MyBusinessObjectBase. MyBusinessObject.cs is never regenerated so you’re free to modify it with your business logic and validations (plus any properties that are not stored in the db). MyBusinessObjectBase is a generated file that will get recreated each time the code gen runs (and update accordingly if you add/remove columns in the database)
For example I create a Customer class that will hold all my customer info. I decide that I’m going to persist the FirstName, LastName, and Age properties. I create a table named Customer to hold these (putting whatever data length and range validations I want on them). Then I rename Customer.cs to a placeholder like Customer.txt. I regen the DAL using NetTiers. I then take the generated Customer class (that will not get overwritten) and drop in the contents of Customer.txt (the part that does my business rules validations).
You’ll probably do two things with the generated business class. First is to override the AddValidationRules method and add any non-data related rules. Second is to write any business domain rules methods and properties that are not stored in the database (like calculated values). Again this class is not overwritten when you regenerate your code, but the generated code will stay in sync with your database adding new properities and modifying data integrity rules along the way (say if you change the length of a field).
The cool thing is that things like the length validations (on properties that are persisted) will already be done for you based on your settings in the database. Go ahead and check out the MyBusinessObjectBase.generated.cs file and you’ll see it’s already written out the AddValidationRules method based on columns in the database (remember to call the base method if you add your own rules in the business class).
Okay, this approach isn’t perfect. It’s not true TDD as in only writing what’s needed. However what does System.Object give you? A bit fat nothing except a unique GetHashCode method and a couple of other useless things. Why not build objects on top of something that has a little extra for you (without having to write it yourself). You do have to make some tradeoffs and for some, it’s too painful to do this. First, you have to bite the bullet that you have a 1:1 relationship of object to table. That’s just the way the NetTiers templates work. Second, you have to have a table (initially and eventually) to generate the code that will do all the data validation but then most business entities have to wind up stored somehow. This technique just helps it along.
You do also have to build your system on top of Enterprise Libraries and some people are not willing to make that leap just yet. Also, some TDD purists will say that you shouldn’t be dependent on this kind of framework but only write what you need when you need it. I agree but this (IMHO) helps. Look at Rocky Lhotka and his CSLA.NET framework. It’s a highly successful business object framework that you could do TDD from. This isn’t that much different from it (other than the fact you need a database to start from). Maybe I’m wrong and this approach is all wrong, but you need to decide that, not some book or blog entry on the interweb.
Finally though, as I mentioned, after all this is said and done I can have my business objects persist with a few lines of code and leverage a validation framework to boot. To me, that’s worth the cost of a one-to-one relationship of table to object and some trade-offs if it means that I can work faster with my business domain and validate it quickly and easily. YMMV.
NOTE: On reading this over now and thinking about it a little more, you might start with a table called Stub. Add an integer ID field and nothing else to it (CodeSmith and NetTiers need at least one column to create something from). Generate the framework from it and base your business objects off the Stub base class (StubBase) rather than creating your own stub like described above. It’ll work in the interim until you have a table of your own for your business class and in the case where you don’t have a table for a business object, you could use this one. Just a thought anyways.
ADDITIONAL NOTE: Thinking even more about the stub idea, you could probably toss away the Data project and Data.SqlClient project and just be left with the Entities project with a business object framework to leverage, but then that’s really no fun is it?
FINAL NOTE: Okay, took me about 4 hours to put this entry together so hope it tweaks your brain and encourages discussion in the community. Maybe I’m completely off my rocker and just talking out of my butt, or maybe not. Anyways, this is a technique I’m using on a current (Enterprise) project and it’s coming along nicely. A combination of using the Composite Application UI Block, NetTiers, Domain Driven Design, and more Unit Tests than you can shake a stick at and I’m pretty confident the project will be a success in many ways.